|
|
Главная
 Статьи
Ссылки
Скачать
Скриншоты
Юмор
Почитать
Tools
Проекты
Обо мне
Гостевая
Форум
Статьи
Ссылки
Скачать
Скриншоты
Юмор
Почитать
Tools
Проекты
Обо мне
Гостевая
Форум

|
При использовании CUDA C API контекст для CUDA создается автоматически при первом вызове какой-либо функции CUDA C API. При дальнейшей работе этот контекст будет использоваться. Однако CUDA C API также предоставляет способ явно уничтожить этот контекст, давая тем самым возможность начать с "чистого листа".
После уничтожения контекста любой вызов CUDA C API приведет к созданию нового контекста. Для уничтожения текущего контекста служит функция cudaDeviceReset.
cudaError_t cudaDeviceReset ( void );
Потоки (stream) внутри CUDA позволяют выполнять различные операции параллельно. Наиболее известный (и полезный) пример - параллельное выполнение ядра с одновременным копированием данных сразу в обе стороны. Для этого мы создаем потоки и помещаем запросы, которые должны выполняться параллельно, в разные потоки. Фактически потоки - это способ обозначения зависимостей между запросами в CUDA - все запросы, которые лежит в одном потоке, должны выполняться строго последовательно, в том порядке, в котором они были заданы. Запросы, из разных потоков, могут выполняться параллельно.
Помимо стандартных способов синхронизации для потоков, есть интересная возможность задания callback-функций. Подобные функции похожи на события (event) в том плане, что они вставляются в поток команд и вызываются после их выполнения. При этом во всех потоках, кроме нулевого, такая функция будет вызвана на CPU сразу же после того, как все команды, посланные в данный поток, завершат свое выполнение. Для нулевого потока callback-функция будет вызвана после завершения всех команд во всех потоках, поданных на выполнения до задания данной callback-функции.
Обратите внимание, что все команды, которые были отправлены на выполнение после вызова callback-функции, не начнут выполняться до тех пор, пока callback-функция не завершит свою работу. Также callback-функция не должна вызывать никаких функция CUDA C API. Ниже приводится простой пример задания такой функции. Обратите внимание, что последний параметр функции cudaStreamAddCallback не используется в настоящее время и должен быть равен нулю.
void CUDART_CB myCallback ( cudaStream_t stream, cudaError_t status, void *data )
{
printf ( "Inside callback %d\n", (size_t)data );
}
...
for ( size_t i = 0; i < 2; i++ )
{
cudaMemcpyAsync ( devPtrIn[i], hostPtr[i], size, cudaMemcpyHostToDevice, stream[i] );
myKernel<<<100, 512, 0, stream[i]>>>( devPtrOut[i], devPtrIn[i], size );
cudaMemcpyAsync ( hostPtr[i], devPtrOut[i], size, cudaMemcpyDeviceToHost, stream[i] );
cudaStreamAddCallback ( stream[i], myCallback, (void*)i, 0 );
}
Все GPU с compute capability 2.х и выше помимо стандартной функции синхронизации потоков внутри блока __syncthreads поддерживают также и ярд дополнительных функций, приводимых ниже.
int __syncthreads_count ( int predicate );
int __syncthreads_and ( int predicate );
int __syncthreads_or ( int predicate );
void __syncwarp ( unsigned int mask = 0xFFFFFFFF );
Каждая из первых трех функций (syncthreads*) осуществляет синхронизацию, как и обычный вызов __syncthreads. Однако кроме этого для каждой из них при вызове вычисляется передаваемого параметра predicate. По значениям этого параметра для каждой нити блока вычисляется возвращаемое функцией значение.
Функция __syncthreads_count возвращает число нитей блока, для которых значение параметра predicate не равно нулю. Функция __syncthreads_and возвращает ненулевое значение тогда и только тогда, когда для каждой нити блока значение predicate не равно нулю. Функция __syncthreads_or возвращает ненулевое значение тогда и только тогда, когда хотя бы для одной нити блока значение predicate не равно нулю.
И наконец функция __syncwarp оперирует уже не на уровне блока, а на уровне отдельного варпа. Она приостанавливает вызывающую нить до тех пор, пока все остальные нити этого варпа также не вызовут эту функцию. Также для GPU класса Volta она выполняет объединение нитей варпа после ветвления - более подробно о специфике Volta будет рассказано в последующих статьях.
Помимо функций, выполняющихся на уровне целого блока и возвращающих значение в зависимости от переданного при вызове параметра для каждой нити, есть также похожие функции, но которые работают уже на уровне отдельного варпа.
Они также принимают на вход целочисленный параметр и сравнивают его с нулем. Возвращаемое ими значение зависит от результатов сравнения с нулем параметров, переданных для каждой нити варпа.
int __all_sync ( unsigned int mask, int predicate );
int __any_sync ( unsigned int mask, int predicate );
int __ballot_sync ( unsigned int mask, int predicate );
int __activemask ();
unsigned int __match_any_sync ( unsigned mask, T value );
unsigned int __match_all_sync ( unsigned mask, T value, int * pred );
Почти все из этих функций принимают на вход целочисленный параметр mask, задающий какие именно нити участвуют в операции, и целочисленный параметр predicate, значение которого сравнивается с нулем.
Функция __all_sync возвращает ненулевое значение, если для всех нитей варпа из mask и не завершивших свое выполнение значение параметра predicate не равно нулю. Функция __any_sync возвращает ненулевое значение, если хотя бы для одной из нитей, указанных в параметре mask и не завершивших свое выполнение значение predicate не равно нулю.
Функция __ballot_sync возвращает целое число? N-ый бит которого равен 1, если нить N еще не завершила выполнение (активна), указана в mask и для нее predicate не равен нулю. Функция __activemask возвращает битовую маску, задающую какая из нитей варпа до сих пор активна (т.е. не завершила свое выполнение).
Функция __match_any_sync (доступна для СС 7.0 и выше) возвращает маску нитей варпа, у которых одно и тоже значение value. Функция __match_all_sync (доступна для СС 7.0 и выше) возвращает mask, если для всех нитей варпа, заданных в mask, переданное значение равно value, иначе возвращается 0. Значение pred устанавливается истинным, если все нитей из mask имеют одно и то же значение value. Иначе для него устанавливается нулевое значение. В этих функциях в качестве типа Т может выступать любой из следующих типов - int, unsigned int, long, unsigned long, long long, unsigned long long, float или double.
В CUDA есть специальный описатель для указателей __restrict__. Данный описатель обозначает, что данный указатель это единственный способ обратиться к соответствующей области памяти (т.е. никакой другой указатель не может ссылаться на эту область памяти). Это позволяет компилятору проводить различные оптимизации кода для повышения быстродействияЮ, а именно убирать избыточные обращения к памяти. Однако следует иметь в виду, что его использование может привести к использованию большего числа регистров.
void foo ( const float * __restrict__ a, const float * __restrict__ b,
float * __restrict__ c );
GPU, начиная с Pascal, поддерживают полноценное использование 16-битовых чисел с плавающей точкой (half). На рис 1. приведено строение значений данного типа. Для того, чтобы использовать этих значений следует подключить заголовочный файл cuda_fp16.h.
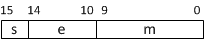
Рис 1. Строение 16-битовых значений с плавающей точкой.
В этом файле определяются два типа - half и half2. Первый изх них соответствует 16-битовому значению с плавающей точкой, а второй - двум таким значениям, занимающим одно 32-битовое слово. Для получения максимального быстродействия рекомендуется использованием всюду где это возможно типа half2, позволяющего выполнять операцию сразу над двумя 16-битовыми значениями.
Для обоих этих типов определено большое количество функций для реализации основных арифметических и трансцендентных функций. При этом обычно каждая такая функция имеет два варианта - один для half и один для half2. Во втором случае к названию функции добавляется "2".
Самым базовыми математическими функциями для этих чисел являются следующие функции, реализующие основные арифметические операции над ними - __hadd, __hadd2, __hdiv, __hfma, __hfma_sat, __hmul, __hmul_sat, __hneg, __hsub, __hsub_sat, __hadd2, __hadd2_sat, __hfma2, __hfma2_sat, __hmul2, __hmul2_sat, __hneg2, __hsub2, __hsub2_sat, __h2div.
Функции, имена которых оканчиваются на _sat, приводят результат операции к отрезку [0,1].
Для сравнения 16-битовых чисел служат следующие функции - __heq, __hequ, __hge, M__hgeu, __hgt, __gtu, __hinf, __hisnan, __hle, __hleu, __hlt, __hltu, __hne, <,b>__hneu. Функции, имена которых заканчиваются на "u", при сравнении NaN возвращают истинное значение, обычные функции - ложное.
Крайне важными функциями для работы с 16-битовыми значениями с плавающей точкой являются фукнции преобразования между 16-битовыми и 32-битовыми значениями, приводимые ниже.
half2 __float22half2_rn ( const float2 a )
half __float2half ( const float a )
half2 __float2half2_rn ( const float a )
half __float2half_rd ( const float a )
half __float2half_rn ( const float a )
half __float2half_ru ( const float a )
half __float2half_rz ( const float a )
half2 __floats2half2_rn ( const float a, const float b )
float2 __half22float2 ( const half2 a )
float __half2float ( const half a )
half2 __half2half2 ( const half a )
int __half2int_rd ( half h )
int __half2int_rn ( half h )
int __half2int_ru ( half h )
int __half2int_rz ( half h )

Copyright © Alexey V. Boreskov 2003-2018