|
|
Главная
 Статьи
Ссылки
Скачать
Скриншоты
Юмор
Почитать
Tools
Проекты
Обо мне
Гостевая
Статьи
Ссылки
Скачать
Скриншоты
Юмор
Почитать
Tools
Проекты
Обо мне
Гостевая

|
За последние несколько лет GPU прошли путь от просто растеризаторов (с возможностью наложения одной текстуры) до мощных процессоров, вычислительная мощность которых в десятки раз превосходит мощность центрального процессора (CPU).
Ключевыми понятиями, позволившими GPU осуществить подобный скачок являются параллелизм и потоковая модель вычислений (stream computing model).
Центральный процессор традиционно ориентирован на последовательную (serial) модель вычислений, когда обработка следующего элемента данных начинается по завершении обработки текущего элемента. Такая модель очень сильно зависит от времени доступа к памяти (latency), и довольно мало выигрывает от большой пропускной способности (bandwidth) памяти - если для обработки элемента необходим доступ к памяти, то процессор вынужден ожидать, когда данные из памяти будут получены.
Для повышения быстродейстия в традиционных процессорах используются многоуровневая кэш-память (довольно большого объема), конвейер с предсказанием (позволяющий начать выполнение следующих команд до завершения текущей). Однако в целом, уровень использования параллелизма в центральном процессоре довольно низок.
Спецификой GPU с самого начала была параллельная обработка данных и наличие графического конвейера. Объем кэш-памяти даже на современных GPU очень мал по сравнению с объемом кэш-памяти центрального процессора.
Параллелизм GPU проявляется сразу на нескольких уровнях - так обработка вершин может происходить параллельно и независимо друг от друга, растеризация примитивов также может быть распараллелена, обработка фрагментов, возникающих при растеризации, тоже происходит независимо друг от друга и, следовательно, может происходить параллельно.
Кроме того, при обработке данных имеет место высокая степень когерентности - так параллельно обрабатываемые фрагменты скорее всего лежат рядом и обращаются к близко расположенным участкам текстуры.
Если посмотреть на архитектуру современных GPU, то сразу видно наличие нескольких независимо работающих вершинных (до 6 на GeForce 6800) и фрагментных (до 16) процессоров, работающих параллельно.
Все это очень хорошо укладывается в так называемую потоковую модель вычислений (stream computing model).
Основой этой модели является понятие потока (stream), как последовательности элементов одного и того же типа.
Так массив координат вершин можно рассматривать как поток (состоящий из четырехмерных векторов). Поток может состоять как из простых элементов, так и сложных.
Над потоком (или набором потоков) можно осуществлять вычисления при помощи ядер (kernel) - ядро берет на вход один или несколько потоков и выдает один или несколько потоков (см. рис 1).

Рис 1. Обработка потоков ядром.
Особенностью вычислений над потоком является то, что обработка одного элемента из потока полностью не зависит от всех остальных элементов этого же потока.
Это обстоятельство позволяет легко распараллеливать обработку потоков - можно использовать несколько независимых процессоров, осуществляющих одновременную обработку нескольких элементов из потока.
Важным свойством потоковой обработки данных является ее сравнительно невысокая зависимость от времени доступа к памяти и хорошая утилизация высокой пропускной способности памяти - время доступа фактически амортизируется на весь поток (т.е. оно влияет лишь в начале обработки потока), в то время как высокая пропускная способность позволяет одновременно обрабатывать много элементов (т.к. каждый элемент требует передачи данных).
Данное свойство важно тем, что время доступа к памяти снижается в среднем на 5% в год, в то время как пропускная способность за год увеличивается в среднем на 25%.
Как легко заметить эффективность потоковых вычислений тем выше, чем больше количество элементов в потоке.
Сложные вычисления в потоковой модели осуществляются путем последовательного соединения нескольких ядер обработки. С точки зрения архитектуры такой подход очень удобен - отдельные ядра занимают небольшие места на чипе, расположенные по соседству друг с другом (что снижает затраты на передачу данных между ними в пределах чипа).
Иллюстрацией последовательного соединения ядер для сложной обработки данных может служить графический конвейер (pipeline) современных GPU (см. рис. 2).
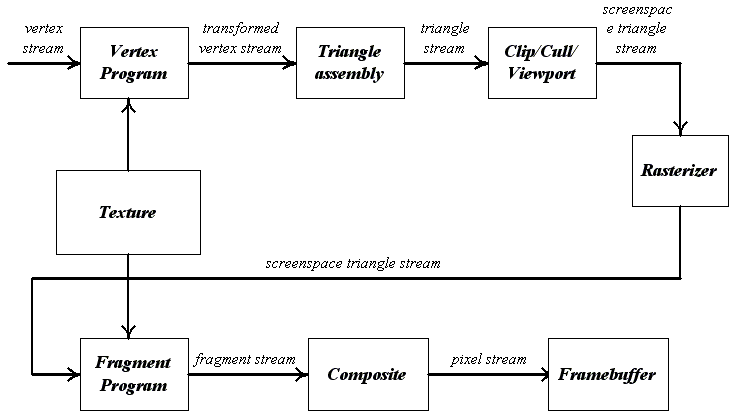
Рис 2. Графический конвейер современных GPU.
Как видно из рисунка, весь конвейер представляет собой последовательность ядер, передающие данные от одного ядра к следующему в виде потоков.
При этом на каждом этапе конвейера возможна параллельная обработка данных, что ведет к высокой эффективности обработки данных.
Довольно важными понятиями при программировании современных GPU являются операции gather и scatter.
Под операцией scatter понимается запись по вычисляемому адресу (например, x [i] = a). Примером такой операции может быть распределение какого-то значения по ряду элементов.
Операция gather - это операция чтения по вычисляемому адресу (например, a = x [i])
Спецификой программирования GPU является то, что в то время как чтение по вычисляемому адресу реализуется довольно легко (как чтение из текстуры, доступное для последних моделей даже для вершинных программ), операции записи по вычисляемому адресу практически невозможна (так фрагментная программа может изменять значения только для одного фрагмента, адрес которого из программы нельзя изменить).
Поэтому для реализации ряда сложных вычислений необходимо модифицировать алгоритм для переводя операций типа scatter в операции gather.
Для реализации ряда эффектов на GPU необходимо использование в вершинных и фрагментных программах различных условных конструкций - операторов if ... else, операторов цикла с заранее неизвестным количеством повторений.
Однако в отличие от традиционных процессоров с последовательной (serial) моделью вычислений реализация этих конструкций на параллельной архитектуре GPU несет в себе ряд сложностей.
Так если обратиться к вершинным и фрагментным программам, вводимым расширениями ARB_vertex_program и ARB_fragment_program, то в них практически полностью отсутствуют условные переходы (да и безусловные также).
Если для фрагментных программ есть команда KIL, позволяющая в зависимости от заданного условия прервать обработку текущего фрагмента и отбросить его, то для вершинных программ нет и этого.
Вместо этого в системе команд есть ряд таких команд, как SGE, SLT, MIN, MAX и CMP. С их использованием можно реализовать целый ряд условных конструкций.
Рассмотрим например следующее выражение:
if ( a < b ) x = a1; else x = a2;
Оно легко реализуется как lerp ( a1, a2, lessThan ( a, b ) ).
Даже на более поздних моделях GPU. поддерживающих условные конструкции, такой способ реализации условных конструкций в целом ряде случаев оказывается предпочтительнее (если вычисление выражений для обоих случаев крайне просто, то такой способ просто укладывается всего в несколько простых команд).
Стандартными способами реализации условных конструкций на параллельных архитектурах является следующие:
Простейшим из этих способов является использование условных кодов. При этом по результатам вычисления условия выставляется флаг, которых влияет на выполнение группы следующих команд. В зависимости от этого флага только одна из возможных ветвей сможет осуществлять запись в регистры.
Т.е. выполняются обе ветви (одна за другой), но только одна из них может произвести запись результатов. На GPU GeForceFX используется именно этот подход для фрагментных программ.
SIMD-реализации позволяют группе параллельно работающих процессоров работать с разными данными, но при этом все они в произвольный момент времени должны выполнять одинаковую команду.
Поэтому, если среди группы одновременно обрабатываемых фрагментов, встречаются как фрагменты для которых условие выполнена, так и фрагменты, для которых условие не выполнено, то будут выполнены обе ветви, но результаты сможет записать лишь одна из ветвей (соответствующая выполненному условию).
Таким образом, в этом случае данный подход практически ничем не отличается от использования условных кодов - так как все процессоры должны выполнять одновременно одну и ту же команду, то будут выполнены обе ветви.
Однако если для всей группы фрагментов условие одновременно выполнено (или для всей группы условие не выполнено), то в этом случае происходит выполнение всего одной ветви, соответствующей выполненному (невыполненному) условию.
Легко видно, что SIMD-подход дает большой выигрыш в случае высокой степени когерентности выполнения условия. В противном случае он фактически сводится к условным кодам.
На процессорах GeForce 6600 для выполнения фрагментных программ используется именно SIMD-подход. На процессорах GeForce FX этот подход используется для выполнения вершинных программ.
Последний подход - MIMD - позволяет отдельным процессорам выполнять разные команды (т.е. они работают совершенно независимо друг от друга). Ясно, что это самый удобный для программиста (но и наиболее сложный в реализации в процессоре) способ реализации условных конструкций.
Этот подход используется на процессорах GeForce 6600 для выполнения вершинных программ.
