|
|
Главная
 Статьи
Ссылки
Скачать
Скриншоты
Юмор
Почитать
Tools
Проекты
Обо мне
Гостевая
Статьи
Ссылки
Скачать
Скриншоты
Юмор
Почитать
Tools
Проекты
Обо мне
Гостевая

|
При работе с большими сценами часто возникает необходимость в различных запросах, связанных с пространственным расположением объектов сцены.
Типичными примерами подобных запросов являются :
Подобные запросы обычно имеют сложность O(n), где n - общее количество объектов в сцене. Однако, в ряде случаев сложность может достигать O(n2) или даже еще более высокой степени.
Из этого видно, что для больших сцен метод "грубой силы" (т.е. прямого перебора) просто неприемлем из-за своих больших затрат.
Таким образом, возникает необходимость в методах с сублинейной сложностью (от общего количества объектов), а в идеале - когда сложность метода прямо пропорциональна количеству объектов, найденных данным запросом (такие методы называются output sensitive).
Стандартным приемом, позволяющим заметно снизить сложность запросов о взаимном расположении объектов в пространстве, являются различные типы так называемых пространственных индексов (spatial index).
Пространственный индекс - это некоторая структура данных (чаще всего иерархическая), строящаяся обычно на этапе подготовки сцены.
Далее мы рассмотрим основные типы пространственных индексов.
Одной из самых простых структур является разбиение всей области пространства (обычно вокруг этой области описывается ограничивающий прямоугольный параллелепипед, который и разбивается) с фиксированным шагом по каждому измерению.
При этом метода область пространства разбивается на n1*n2*n3 прямоугольных ячеек (cells) одинакового размера.
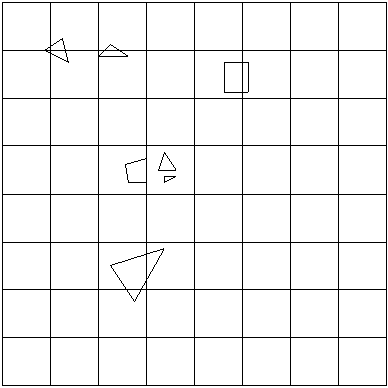
Рис 1. Регулярное разбиение в двухмерном случае.
Для каждой такой ячейки создается список всех объектов, имеющих с ней непустое пересечение. Таким образом, данная структура фактически представляет собой трехмерный массив, элементами которого являются списки объектов.
Обычно, более удачным способом представления такого индекса является использование хэш-таблиц, в которых хранятся только не пустые списки.
Тогда для определения всех объектов, удовлетворяющих какому-то запросу (например, пересекающему заданное тело), сперва составляется список всех таких ячеек, только в которых может содержаться интересующие нас объекты (например, пересекающих ограничивающее тело, описанное вокруг объекта, пересечение с которым мы ищем).
После получения списка ячеек, строится список объектов, являющийся объединением списков объектов для соответствующих ячеек, и все объекты из этого списка непосредственно проверяются на выполнение условия поиска (например, пересечения заданного объекта).
Подобный подход позволяет крайне быстро находить все интересующие нас объекты (фактически, при удачном подборе шагов разбиения можно для широкого класса запросов получить оценку O(1)).
Одним из свойств этой структуры является ее устойчивость по отношению к локальным изменениям геометрии сцены (например, небольшому перемещению нескольких объектов).
В этом случае, в силу локальности изменения, затронутыми оказываются всего лишь несколько ячеек, списки объектов для которых легко корректируются.
Именно такой подход, использующий регулярное разбиение пространства, был использован в игре Wolfenstein 3D для решения задачи удаления невидимых поверхностей.
Одним из самых серьезных недостатков регулярного разбиения пространства является то, что он практически никак не привязывает само разбиение к структуре сцены.
Это выражается в том, что как части сцены, в которых очень много небольших объектов, так и совершенно пустые области разбиваются с одинаковым шагом.
И то, и другое может заметно снизить эффективность применения регулярного разбиения пространства.
Это приводит с одной стороны к появлению совершенно пустых ячеек, а с другой - к появлению ячеек, с огромными списками объектов.
Если использование хэш-таблиц позволяет не тратить ресурсы (память и время) на хранение и обработку пустых ячеек, то бороться с ячейками, содержащими огромное число небольших объектов значительно сложнее.
Поэтому хотелось бы варьировать степень разбиения в зависимости от структуры сцены в данной области. Это может позволить использовать очень большой шаг разбиения в относительно пустых областях сцены с одной стороны, а с другой - использовать мелкий шаг разбиения в густо заполненных частях сцены.
Именно такую возможность и предоставляют различные иерархические структуры (деревья). Одним из простейших типов таких иерархических структур являются восьмеричные деревья (octtrees).
Данный подход заключается в рекурсивном разбиении области сцены (обычно разбивается ее ограничивающий прямоугольный параллелепипед - AABB) на 8 равных частей.
Каждая из этих частей разбивается таким же образом и так далее.
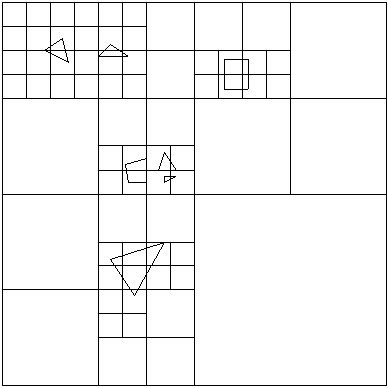
Рис 2. Восьмеричное дерево.
Этот рекурсивный процесс разбиения продолжается до тех пор, пока либо количество объектов в очередной ячейке разбиения не окажется меньше заданного, либо пока размер ячейки (или глубина дерева) не дойдет до заранее заданной величины.
Процесс построения восьмеричного дерева может быть представлен следующим фрагментов псевдокода:
def buildOcttree ( objects, box ):
boxes = splitBox ( box )
lists = range ( 8 )
for i in range ( 8 ):
lists [i] = []
for obj in objects:
for i in range ( 8 ):
if obj.overlaps ( boxes [i] ):
lists [i].append ( obj )
node = OcttreeNode ( objects, box )
for i in range ( 8 ):
if list [i].size >= countThreshold and boxes [i].size >= sizeThreshold:
node.child [i] = buildOcttree ( lists [i], boxes [i] )
else:
node.child [i] = None
return node
Восьмеричное дерево довольно хорошо адаптируется к различным типам сцен, при этом характерное время выполнения запроса к нему равно O(log n), большинство операций над ним носит рекурсивный характер.
Процесс определения объектов, находящихся в заданном ограничивающем теле может быть представлен следующим фрагментов псевдокода:
def objectsInBox ( node, box, list ):
if node.isLeaf ():
list = list + node.objects
return list
for i in range ( 8 ):
if box.overlaps ( node.child [i].box ):
objectsInBox ( node.child [i], box, list )
return list
В случае, когда существенны лишь два измерения (например, при работе с ландшафтами), можно применять так называемое тетрарное дерево (quadtree). При построении этого дерева двухмерная область на каждом шаге разбивается на четыре равных части.
Одним из недостатков восьмеричного (и тетрарного) дерева заключается в том, что разбиение области каждый раз проводится сразу по всем трем осям. В случае, когда размеры сцены по разным осям заметно отличаются, то мы получаем довольно неэффективное разбиение.
Одним из проявлений неэффективности в этом случае может оказаться ситуация, когда размер ячейки по одному из измерений оказывается больше типичного размера объекта. В этом случае мы получаем что списки объектов, соответствующие этому разбиению будут практически совпадать.
Как уже было отмечено, основным недостатком восьмеричного дерева является то, что разбиение происходит сразу по всем трем плоскостям, независимо от размера разбиваемой ячейки.
В отличие от этого, так называемые kD-деревья на каждом шаге производят разбиение только вдоль одной плоскости. Обычно в качестве плоскости разбиения выбирается плоскость, перпендикулярная оси, вдоль которой ячейка имеет наибольший размер (см. рис. 3).
Рис 3. Разбиение ячейки для kD-дерева.
При использовании такой стратегии разбиения пропадает основной недостаток восьмеричного дерева - возможность возникновения ячеек с сильно отличающимися размерами вдоль разных измерений но сохраняются все его преимущества - адаптивный характер разбиения и временные затраты O(log n).
За счет этого подхода, у нас гарантированно будут получаться ячейки, размеры которых вдоль различных осей, не будут сильно отличаться.
Кроме того, у kD-деревьев есть еще одна интересная особенность - не обязательно каждый раз разбивать ячейку на две равные половинки. Вместо этого можно также использовать адаптивный алгоритм - выбирать такое положение разбивающей плоскости вдоль оси разбиения, при котором в получившихся половинках будет примерно одинаковое число объектов.
Кроме того, дочерние узлы для произвольного узла kD-дерева гораздо проще упорядочить, чем в случае восьмеричного дерева.
Несмотря на все эти различия, восьмеричное дерево может считаться частным случаем kD-дерева, у которого происходит чередование направлений разбиения (некоторые именно так и определяют kD-дерево).
Ниже приводится фрагмент псевдокода для построения kD-дерева.
def buildKdTtree ( objects, box ):
axis = box.getMainAxis ()
plane = box.getSplitPlaneForAxis ( axis )
boxes = box.splitWithPlane ( plane )
l1 = []
l2 = []
for obj in objects:
if boxes [0].overlaps ( obj.box ):
l1.insert ( obj )
if boxes [1].overlaps ( obj.box ):
l2.insert ( obj )
node = KdTreeNode ( objects, box )
if len ( l1 ) > 0:
node.child [0] = buildKdTree ( l1, boxes [0] )
else:
node.child [0] = None
if len ( l2 ) > 0:
node.child [1] = buildKdTree ( l2, boxes [1] )
else:
node.child [1] = None
return node
При реализации как восьмеричных, так и kD-деревьев возможны два разных подхода к случаю, когда разбивающая плоскость пересекает один из объектов сцены.
Первый подход заключается в разбиении исходного объекта на две части, каждая из которых идет в соответствующий узел.
Второй подход вместо разбиения объекта просто помещает ссылку на него в оба соответствующих списка.
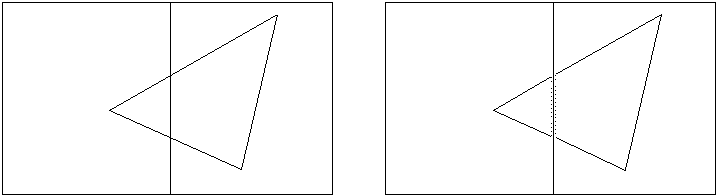
Рис 4. Пересечение разбивающей плоскостью объекта.
Основным плюсом первого подхода является однозначная классификация объектов по узлам. При этом списки для дочерних узлов заданного узла никогда не пересекаются и возможно очень легкое построение частичного упорядочивания объектов - всегда можно утверждать, что ни один из объектов из одного (более удаленного) узла никогда не сможет закрыть никакого объекта из другого узла.
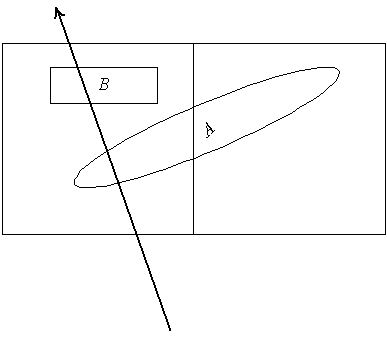
Рис 5. Объект из более дальнего узла закрывает объект из ближнего узла.
Кроме того, при втором подходе необходимо отслеживать какие объекты уже были обработаны (так как мы можем снова встретить ссылку на этот объект в списке другого узла).
Зато второй подход не чувствителен к локальным изменениям геометрии сцены - достаточно просто откорректировать списки объектов для соответствующих узлов дерева.
В первом подходе это не так - исходный объект уже разбит. Поэтому нам надо либо еще раз разбивать части объекта, либо хранить где-то копию исходного объекта и разбивать ее.
И то, и другое довольно неудобно, кроме того, разбиение объектов заметно увеличивает общее число объектов, что также довольно плохо с точки зрения производительности.
Еще одним из распространенных пространственных индексов являются BSP (Binary Space Partitioning) деревья (деревья двоичного разбиения пространства).
При построении этого дерева выбирается некоторая плоскость и все объекты разбиваются на два кластера, в зависимости от положения по отношению к этой плоскости. Объекты, пересекаемые плоскостью, разбиваются вдоль нее.
К каждому из двух полученных множеств вновь применяется подобный процесс разбиения и так далее.
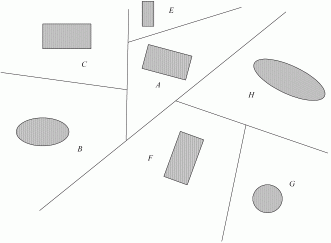
Рис 6. Построение BSP-дерева.
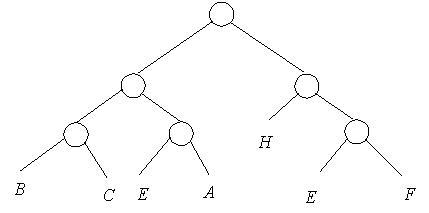
Рис 7. Дерево для сцены с рисунка 6.
Таким образом BSP-дерево фактически является разновидностью kD-дерева (или наоборот), однако здесь нет жесткого правила выбора разбивающей плоскости.
Одним из наиболее часто встречающихся случаев использования BSP-деревьев является построение дерева по набору граней (именно этот подход и был использовался в играх Doom и Quake).
В этом случае в качестве разбивающей плоскости выбирается плоскость, проходящая через одну из граней. Довольно часто критерием выбора грани, является минимизация числа разбиений на данном шаге.
Ниже приводится процедура построения подобного BSP-дерева.
def buildBspTtree ( objects ):
plane = chooseBestSplitter ( objects ).plane
front = []
back = []
node = BspTreeNode ( objects, plane )
for obj in objects:
if plane.classify ( obj ) == IN_FRONT:
front.insert ( obj )
elif plane.classify ( obj ) == IN_BACK:
back.insert ( obj )
else:
objs = obj.splitWith ( plane )
front.insert ( objs [0] )
back.insert ( objs [1] )
if len ( front ) > 1:
node.front = buildBspTree ( front )
else:
node.front = None
if len ( back ) > 1:
node.back = buildBspTree ( back )
else:
node.back = None
return node
При построении BSP-деревьев возможно два критерии прекращения рекурсии.
1. В списке узла осталось не более одной грани.
2. Все оставшиеся в списке узла грани являются частью границ выпуклого многогранника.
Оба этих критерия связаны с тем, что BSP-дерево для граней задумывалось как механизм сортировки граней. В этом случае ясно, что критерием остановки должна быть однозначная упорядочиваемость всех граней узла по отношению к произвольному положению камеры.
При этом видно, что для критерия 1 оставшиеся в узле грани (либо одна, либо ни одной) однозначно упорядочиваются.
Для второго критерия хотя такого однозначно упорядочивания может и не быть, но из лицевых граней узла, ни одна не может закрывать другую, тем самым они все равно упорядочиваемы.
Если при использовании первого подхода в качестве листьев дерева у нас выступают фактически сами грани, то во втором случае листьями дерева становятся выпуклые многогранники, на которые дерево разбивает всю сцену.
Пи этом второй подход приводит к деревьям меньшего размера и работать с такими деревьями оказывается во многих случаях проще. Именно поэтому деревья этого типа (их обычно называют листьевыми, leafy) используются чаще.
Во всех играх Doom и Quake использовались именно листьевые BSP-деревья.
На следующем рисунке приводятся сцена, ее разбиение и соответствующее ей листьевое BSP-дерево.

Рис 8. Сцена и ее листьевое BSP-дерево.
Еще одним вариантом иерархического пространственного индекса являются так называемые иерархии ограничивающих объемов (Bounding Volume Hierarchies).
В отличии от ранее рассмотренных деревьев, у BVH нет определенного порядка - количество дочерних узлов у узла дерева может меняться и заранее жестко не зафиксировано.
Также у BVH-деревьев нет разбивающей плоскости.
При построении BVH вокруг исходной группы объектов описывается некоторое ограничивающее тело. После этого группа разбивается на несколько подгрупп, вокруг каждой из которых описывается свое ограничивающее тело. Далее каждая из них снова разбивается на подгруппы и так далее.
В результате мы получаем дерево, где с каждым узлом связано некоторое ограничивающее тело и набор дочерних узлов.
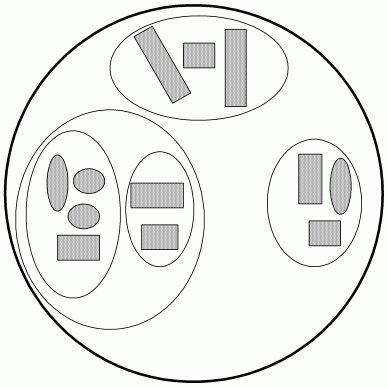
Рис 9. Пример BVH.
Обратите внимание, что ограничивающие тела для дочерних узлов могут пересекаться, в то время как списки объектов для них - нет.
Существует несколько различных вариантов построения иерархии ограничивающих тел, наиболее известным является метод Голдсмита-Салмона. Ниже приводится псевдокод для одного из самых простых способов построения BVH.
def buildBvh ( objects ):
box = buildBoxForObjects ( objects )
axis = box.getMainAxis ()
plane = box.getSplitPlaneForAxis ( axis )
boxes = box.splitWithPlane ( plane )
l1 = []
l2 = []
for obj in objects:
if boxes [0].overlaps ( obj.box ):
l1.insert ( obj )
if boxes [1].overlaps ( obj.box ):
l2.insert ( obj )
node = BvhNode ( objects, box )
if len ( l1 ) > 0:
node.child [0] = buildBvhTree ( l1, boxes [0] )
else:
node.child [0] = None
if len ( l2 ) > 0:
node.child [1] = buildBvhTree ( l2, boxes [1] )
else:
node.child [1] = None
return node
Как видно, это вариант очень похож на процедуру построения kD-дерева.
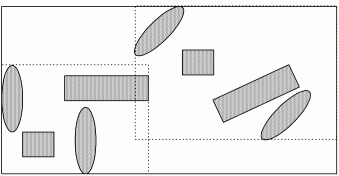
Рис 10.
В самом простейшем случае одномерных интервалов (сегментов) interval tree выступает в качестве пространственного индекса, используемого для работы с большим количеством (возможно пересекающихся между собой) отрезков.
Существует два варианта построения одномерных interval tree.
В первом случае мы выбирает некоторое значение xc и делим весь набор отрезков на три части - L (все отрезки целиком лежащие левее xc), R (все отрезки целиком лежащие правее xc) и C (все отрезки, пересекающие xc).
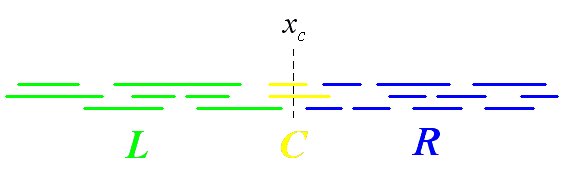
Рис 11. Разбиение отрезков для построение interval tree.
После этого список C связывается с текущим узлом дерева, а по L и R строятся левое и правое поддеревья аналогичным образом.
def buildIntervalTree ( segments ):
if len (segments) == 0:
return None
min, max = findExtent ( segments )
xc = (min + max) / 2
l = []
r = []
c = []
for seg in segments:
if seg.start < xc:
l.append ( seg )
elif seg.end > xc:
r.append ( seg )
else:
c.append ( seg )
node = IntervalTreeNode ()
node.xc = xc
node.c = c
node.left = buildIntervalTree ( l )
node.right = buildIntervalTree ( r )
return node
Второй вариант использует обычное бинарное дерево для упорядочивания отрезков по их началу, но при этом для каждого узла дерева хранится максимальная правая координата для всех отрезков соответствующего поддерева.
Оба этих способа обеспечивают быстрое построение дерева по набору отрезков и логарифмическую скорость локализации интересующих отрезков (кроме вырожденных случаев).
Оба описанных подхода легко обобщаются и на многомерный случай - в этом случае вместо отрезков у нас выступают многомерные AABB.
Еще одним вариантом деревьев, используемых для поиска на плоскости или в пространстве, являются так называемые R-деревья.
R-дерево строится по ограничивающим прямоугольным параллелепипедам (AABB) исходных объектов и во многом напоминает B-деревья.
Каждый узел R-дерева порядка (m,M) содержит от m до M записей (корень дерева может содержать до двух записей), с каждой записью связан AABB для всех объектов соответствующего поддерева и ссылка на узел этого поддерева.
В отличии от B-деревьев AABB, соответствующие записям (поддеревьям) могут пересекаться между собой. В остальном работа с R-деревьями сильно напоминает работу с B-деревьями - при добавлении новой записи может произойти переполнение узла и тогда необходимо его разбить на два (вынеся ссылку на добавленную запись наверх), при уничтожении записи может возникнуть необходимость объединения узла с соседним (в этом случае наверху удаляется ссылка).
Для случая переполнения узла существует две стратегии разбиения всех AABB по двум получившимся узлам. Обе они основаны на выборе двух AABB, задающих изначальные группы. После чего каждый из оставшихся AABB добавляется к той группе, для которой его добавление дает минимальное увеличение итоговой площади получающегося AABB.
Первая стратегие (квадратичная) заключается в выборе той пары AABB bi и bj, которые дают наибольшую площадь, если они окажутся в одной группе.
Вторая стратегия (линейная) заключается в выборе bi и bj, обладающих наибольшим расстоянием вдоль каждой оси.
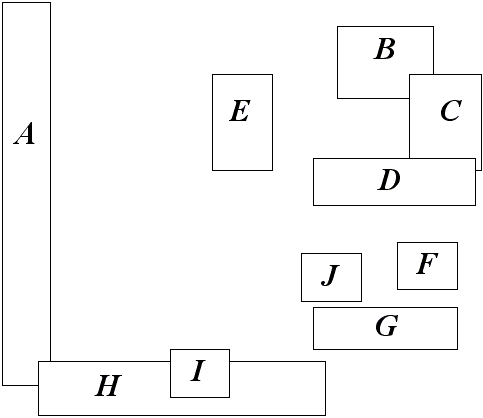
Рис 12. Пример исходных данных для построения R-дерева.
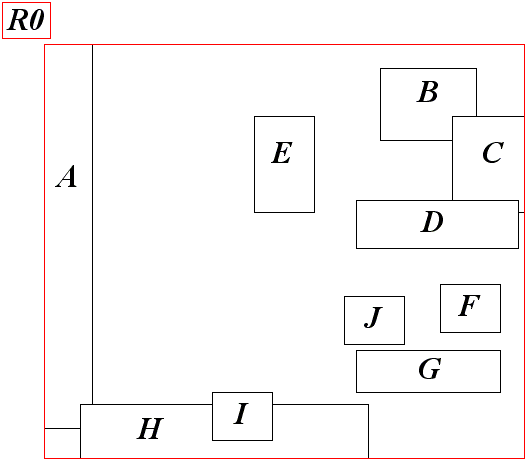
Рис 13. Корневой узел R-дерева.
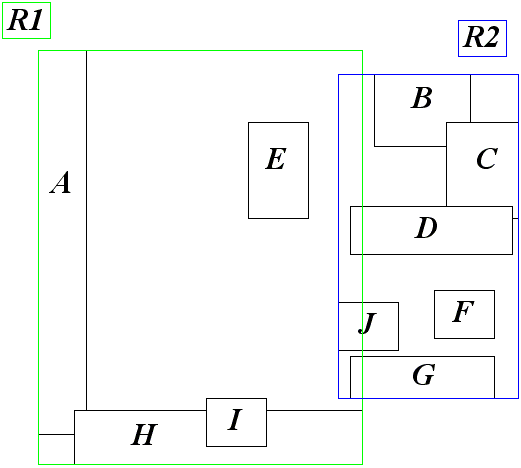
Рис 14. Следующий уровень R-дерева.
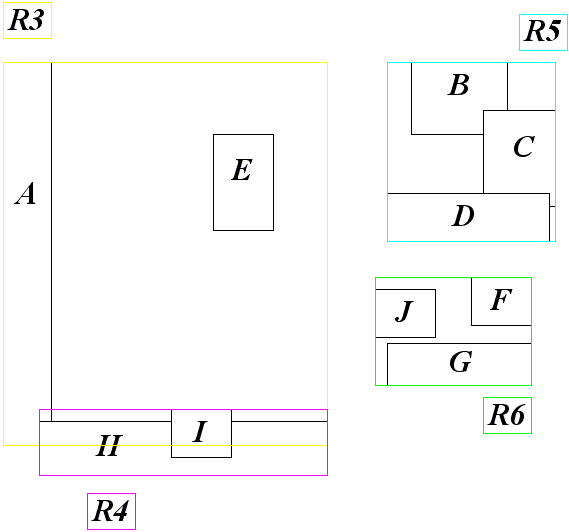
Рис 15. Следующий уровень R-дерева.
Рис 16. Итоговое R-дерево.
Как можно заметить R-деревья не гарантируют ларифмическу скорость (в худшем случае), но на реальных данных ведут себя хорошо. Типичным применением для R-деревьев являются различные СУБД по пространственным данным (анпримемр различные геоинформационные системы).
Все рассмотренные выше иерархические структуры имеют между собой целый ряд общих черт.
Также довольно часто встречаются различные смешанные структуры, комбинирующие в себе несколько рассмотренных выше структур.
Одним из вариантов этого является построение восьмеричного дерева по граням сцены с разбиением объектов, после чего для каждого листа дерева по всем содержащимся в нем граням строится BSP-дерево.
Данный подход позволяет легко получать точно упорядочения объектов для любого положения наблюдателя.
