|
|
Главная
 Статьи
Ссылки
Скачать
Скриншоты
Юмор
Почитать
Tools
Проекты
Обо мне
Гостевая
Форум
Статьи
Ссылки
Скачать
Скриншоты
Юмор
Почитать
Tools
Проекты
Обо мне
Гостевая
Форум

|
Одним из базовых понятий в CUDA является сетка нитей (grid), запускаемая на GPU. При этом сама эта сетка запускается с CPU в асинхронном режиме (т.е. запрос на запуск просто ставится в очередь и управление немедленно возвращается). За счет запуска сеток в различных потоках (stream) можно обеспечить параллельное выполнение нескольких сеток на GPU.
Такая схема очень проста и хорошо подходит для целого ряда вычислительных задач. Однако встречаются и такие задачи, доля которых эта модель параллелизма является ограничивающей. Одним из таких примеров является проведение расчета на нерегулярных сетках. Подобные сетки применяются когда расчет на сетках с постоянным шагом является слишком неэффективным и хочется в отдельных местах проводить расчеты с заметно меньшим шагом.

Рис 1. Пример нерегулярной сетки
С целью поддержки подобного рода задач начиная с CUDA 5 поддерживается так называемый динамический параллелизм. Под ним понимается возможность запуска новых сеток прямо на стороне GPU, фактически любая нить сетки может запустить новую сетку. Для запуска сетки с заданным ядром со стороны GPU используется тот же самый синтаксис, что и для традиционного запуска сетки с CPU.
Каждая нить может запустить сетку нитей (и не одну). При этом сам запуск, как и ранее, является асинхронным, сетка просто ставится в очередь и управление немедленно возвращается в вызвавшую нить. Сетка, запустившая новую сетку, называется родительской, а сама запускаемая сетка называется дочерней.
Важным свойством запускаемых сеток является то, что все эти запуски являются вложенными(fully nested). Это значит, что все дочерние сетки гарантированно завершатся перед завершением родительской сетки (рис. 2).
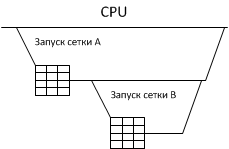
Рис 2. Вложенность сеток
Также у родительской сетки есть возможность явно дождаться завершения работы дочерней сетки при помощи вызова cudaDeviceSynchronize. При этом обратите внимание, что если сразу несколько нитей блока запускают дочерние сетки, то может возникнуть ситуация, когда к моменту вызова cudaDeviceSynchronize не все из этих нитей успеют произвести запуск.
Чтобы избежать такой ситуации (если сразу несколько нитей одновременно запускают сетки) перед вызовом cudaDeviceSynchronize следует вызвать __syncthreads. Точно также и после вызова cudaDeviceSynchronize следует также вызвать __syncthreads.
__syncthreads ();
if ( threadIdx.x == 0 ) // issue synchronize from thread 0
cudaDeviceSyncrhonize ();
__syncthreads ();
Обратите также внимание, что сам вызов cudaDeviceSynchronize это довольно дорогостоящая операция, поэтому этот вызов следует делать только тогда, когда это действительно необходимо.
При запуске дочерней сетки CUDA гарантирует, что как при запуске дочерней сетки, так и при ее завершении, и дочерняя и родительская сетки одинаково видят глобальную память. Т.е. если родительская сетка запишет что-то в глобальную память и после этого запустит дочернюю, то дочерняя сетка гарантированно это увидит. Аналогично, если дочерняя сетка запишет что-то в глобальную память, то после ее завершения родительская сетка это увидит. Однако это не верно во время выполнения дочерей сетки.
CUDA накладывает некоторые ограничения на то, какие типы указателей можно передавать дочерней сетке из родительской. Нельзя передавать указатели на разделяемую память и на локальные переменные (в т.ч. и переменные, размещенные на стеке).
__device__ int v1; // device variable
__global__ void parentKernel ()
{
int v2; // local variable
__shared__ int v3; // shared variable
childKernel<<<1, 512>>> ( &v1 ); // allowed
childKernel<<<1, 512>>> ( &v2 ); // NOT allowed
childKernel<<<1, 512>>> ( &v3 ); // NOT allowed
}
По умолчанию все дочерние сетки, запущенные блоком, выполняются последовательно, одна за другой, даже если эти дочерние сетки запускаются разными нитями блока. Однако, как и при запуске сеток со стороны CPU, для каждого запуска можно указать в каком именно потоке (stream) следует выполнять данную сетку. Используемые для этого потоки необходимо создавать и уничтожать на стороне GPU. Кроме того, они должны создаваться как неблокирующие, как это показано ниже.
cudaStream_t stream;
cudaStreamCreateWithFlags ( &stream, cudeStreamNonBlocking );
Обратите внимание, что потоки, созданные нитями из разных блоков, считаются разными. При этом не гарантируется, что соответствующие дочерние сетки на самом деле будут выполняться параллельно.
Использование динамического параллелизма ведет к появлению рекурсии. При этом на самом деле есть два разных вида глубины такой рекурсии - глубина вложенности и глубина синхронизации. На самом деле они могут различаться, при превышении максимальной глубины синхронизации вызов cudaDeviceSynchronize приведет к ошибке.
Для сборки приложения с использованием динамического параллелизма нужно указать дополнительные опции. Ниже приводится командная строка для сборки 64-битового приложения.
nvcc test.cu --machine 64 --debug --gpu-architecture=sm_35 -rdc=true -lcudadevrt -o test
Ниже приводится листинг простого приложения, демонстрирующего использование динамического параллелизма - каждая нить запускает новую сетку с тем же ядром, но измененными параметрами. При этом каждая нить печатает свой номер и свои параметры.
#include <stdio.h>
__global__ void kernel ( int level, float a )
{
printf ( "Thread %d level %d value %f\n", threadIdx.x, level, a );
if ( level == 0 )
kernel <<<1, 5>>> ( level + 1, a*a );
}
int main ()
{
kernel<<<1, 5>>> ( 0, 3 );
cudaDeviceSynchronize ();
printf ( "Success\n" );
return 0;
}

Copyright © Alexey V. Boreskov 2003-2018