|
|
Главная
 Статьи
Ссылки
Скачать
Скриншоты
Юмор
Почитать
Tools
Проекты
Обо мне
Гостевая
Форум
Статьи
Ссылки
Скачать
Скриншоты
Юмор
Почитать
Tools
Проекты
Обо мне
Гостевая
Форум

|
Одной из классических параллельных операция является операция редукции (reduce). В простейшем случае она является просто сложением всех элементов заданного массива. Есть классическая реализация алгоритма параллельной редукции на CUDA. В этой реализации каждый блок нитей суммирует определенную часть входного массива (обычно 512-1024 элементов). При этом для выполнения параллельного суммирования используется разделяемая (shared) память, работа с которой требует постоянной синхронизации.
Начиная с архитектуры Kepler (600 и 700 серии GeForce)поддерживается новая команда - shuffle (SHFL). Данная команда позволяет быстро обмениваться данными между нитями одного варпа (warp). Для этого не требуется никакой разделяемой памяти и явной синхронизации.
Фактически просто происходит чтение соответствующего регистра другой нити варпа. Данная операция быстра и позволяет передавать как передачу значений от одной нити другой, так и передачу значения от одной нити всем остальным (broadcast).
Данная функциональность была слегка изменена в CUDA 9 - вместо функций __shfl(), __shfl_down(), __shfl_up() и __shfl_xor() были введены следующие функции (отличающиеся кроме названия также добавлением первого параметра):
T __shfl_sync ( unsigned int mask, T var, int srcLane, int width = warpSize ); T __shfl_up_sync ( unsigned int mask, T var, unsigned int delta, int width = warpSize ); T __shfl_down_sync ( unsigned int mask, T var, unsigned int delta, int width = warpSize ); T __shfl_xor_sync ( unsigned int mask, T var, int laneMask, int width = warpSize );
В качестве типа T могут выступать типы int, unsigned int, long, unsigned long, long long, unsigned long long, float и double. Если подключить заголовочный файл cuda_fp16.h, то также в качестве T можно будет использовать типы __half и __half2.
Все эти команды обеспечивают обмен значениями переменной (фактически - регистра) внутри варпа. Обратите внимание, что данный обмен выполняется для всех активных нитей варпа, выполняющих соответствующую команду, и заданных в битовой маске mask.
Для обозначения номера нити внутри варпа а англоязычной литературе обычно используется термин lane, возможными значениями являются целые числа от 0 до warpSize-1. Все рассматриваемые четыре функции принимают необязательный параметр width|. Допустимыми значениями для этого параметра являются целочисленные степени двух, не превышающие warpSize (т.е. числа 1, 2, 4, 8, 16 и 32). Данный параметр позволяет фактически разбить весь варп на несколько областей и обмен значениями будет происходить внутри каждой такой области независимо.
Рассматриваемые функции отличаются фактически только способом вычисления номера нити внутри варпа, из которой будет произведено чтение значения. каждая из этих функций возвращает значение, прочитанное из заданной переменной нити, с вычисленным номером. Если соответствующий номер нити является недопустимым или соответствует уже завершившейся нити, то результат чтения будет не определен.
Функция __shfl_sync возвращает значение переменной из нити, номер которой задан в параметре srcLane. Если значение width меньше, чем warpSize, то весь варп делится на части размером width и внутри каждой такой части нумерация нитей начинается с нуля. Если значение параметра srcLane лежит вне диапазона [0,warpSize-1], то возвращается значение из нити с номером srcLane % width.
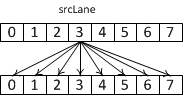
Рис 1. Работа __shfl_sync.
Функция __shfl_down_sync вычисляет номер нити, из которой будет взято значение, путем прибавления параметра delta к номеру текущей нити (рис 2).
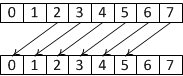
Рис 2. Работа __shfl_down_sync.
Функция __shfl_up_sync вычисляет номер нити, из которой будет взято соответствующее значение, просто вычитая величину delta из номера текущей нити.
Функция __shfl_xor_sync вычисляет номер нити путем применения побитовой операции XOR с параметром laneMask к номеру текущей нити.
Одним из простейших пример использования этих функций является "раздача" значения с одной из нитей варпа всем остальным нитям этого варпа без использования разделяемой памяти и синхронизации. Ниже приводится соответствующий пример кода.
int lane - threadIdx.x & (warpSize - 1); // get lane
int value;
if ( lane == 0 ) // use lane 0 to broadcast value
value = arg; // load value for lane 0
// broadcast for all threads from lane 0
value = __shfl_sync ( warpSize-1, value, 0 );
Еще одной областью применения этих функций является вычисление редукции, т.е. суммы элементов массива (в общем случае вместо сложения может использоваться любая бинарная ассоциативная операция). Рассмотрим сначала, как можно найти сумму значений, соответствующих нитям одного варпа. На следующем рисунке приводится диаграмма параллельного суммирования значений (чтобы не делать рисунок слишком громоздким рассматривается массив не из 32, а всего из 8 значений).
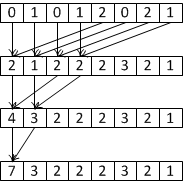
Рис 2. Иерархическое суммирование массива.
Ниже приводится фрагмент кода, вычисляющий сумму значений для всех нитей одного варпа, при этом считается, что каждая нить держит свое значение в переменной val.
for ( int offset = warpSize/2; offset > 0; offset /= 2 )
val += __shfl_down_sync ( warpSize - 1, val, offset );
В результате выполнения данного фрагмента кода мы получим итоговую сумму только в переменной val нити с номером 0. Если мы хотим получить сумму сразу во всех нитях варпа, то вместо функции __shfl_down_sync нужно использовать функцию __shfl_xor_sync:
for ( int mask = warpSize/2; mask > 0; mask /= 2 )
val += __shfl_xor_sync ( warpSize-1, val, mask );
Соответствующий фрагмент кода можно оформить в виде inline-функции:
__inline__ __device__ int warpReduceSum ( int val )
{
for ( int offset = warpSize/2; offset > 0; offset /= 2 )
val += __shfl_down_sync (warpSize-1, val, offset );
return val;
}
На основе этой функции легко можно реализовать суммирование всех элементов массива, соответствующих нитям блока. При этом мы будем использовать небольшой массив разделяемой памяти, в который каждый варп будет записывать свой результат.
__inline__ __device__ int blockReduceSum ( int val )
{
static __shared__ int shared [32];
int lane = threadIdx.x % warpSize;
int wid = threadIdx.x / warpSize;
val = warpReduceSum ( val );
// write reduced value to shared memory
if ( lane == 0 )
shared [wid] = val;
__syncthreads();
// ensure we only grab a value from shared memory
// if that warp existed
val = (threadIdx.x<blockDim.x/warpSize) ? shared[lane] : int(0);
if ( wid == 0 )
val = warpReduceSum ( val );
return val;
}
Теперь задача суммирования всех чисел из большого массива легко сводится к двум вызовам следующего ядра:
__global__ void deviceReduceKernel ( int * in, int * out, int n )
{
int sum = 0;
//reduce multiple elements per thread
for ( int i = blockIdx.x * blockDim.x + threadIdx.x; i < n; i += blockDim.x * gridDim.x )
sum += in[i];
sum = blockReduceSum ( sum );
if ( threadIdx.x == 0 )
out [blockIdx.x] = sum;
}
Для нахождения суммы всего массива на GPU можно использовать следующую функцию (обратите внимание, что требуется вспомогательный массив, в котором каждому блоку нитей соответствует один элемент):
void deviceReduce ( int * in, int * out, int n )
{
int threads = 512;
int blocks = min((n + threads - 1) / threads, 1024);
deviceReduceKernel<<<blocks, threads>>> ( in, out, n );
deviceReduceKernel<<<1, 1024>>> ( out, out, blocks );
}
По этой ссылке можно скачать весь исходный код к этой статье.

Copyright © Alexey V. Boreskov 2003-2017