|
|
Главная
 Статьи
Ссылки
Скачать
Скриншоты
Юмор
Почитать
Tools
Проекты
Обо мне
Гостевая
Статьи
Ссылки
Скачать
Скриншоты
Юмор
Почитать
Tools
Проекты
Обо мне
Гостевая

|
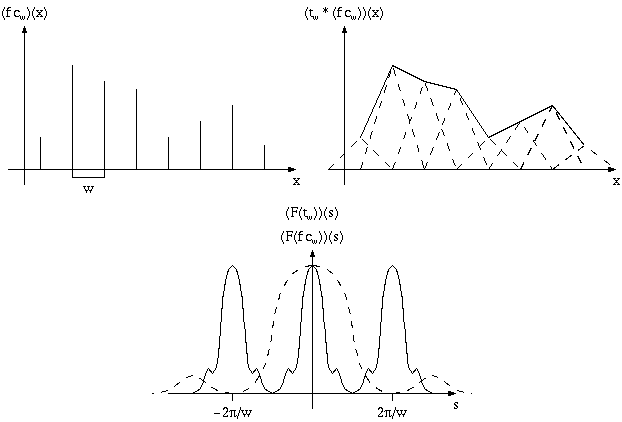
Практически все, с чем приходится иметь дело на компьютере, представляет собой дискретизированную функцию (т.е. значения некоторой функции на заданном множестве точке - сетке или решетке).
В частности все изображения и текстуры на самом деле представляют собой значения 1-2-3-мерных функций на растровой сетке.
Простое восприятие этих величин как массива чисел довольно часто ведет к появлению т.н. погрешностей дискретизации (aliasing artifacts).
Для того, чтобы понять происхождение этих погрешностей и способы борьбы с ними существует соответствующий математический аппарат, называемый sampling theory.
Sampling theory как раз и рассматривает работу с набором значений (samples) функции и широко применяется не только в компьютерной графике.
Фундаментальным математическим понятием, на которое опирается sampling theory, является преобразование Фурье, которое можно рассматривать как разложение заданной функции на множество гармоник (в общем случае это множество гармоник имеет мощность континуум).
Данное преобразование, обозначаемое в дальнейшем через F, сопоставляет произвольной функции f(x) другую функцию F(f)(w), задаваемую следующим уравнением:
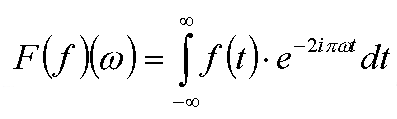
Обратите внимание, что в общем случае получаемая при помощи преобразования Фурье является комплекснозначной (хотя если исходная функция четна, то и ее образ Фурье будет вещественнозначной четной функцией).
Также вводится обратное преобразование Фурье F-1(f), позволяющее восстановить исходную функцию по ее образу Фурье (спектру). Обратное преобразование Фурье задается следующей формулой:
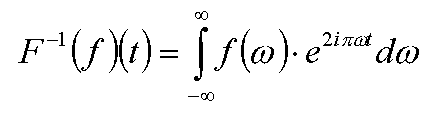
Еще одним важным понятием, которое нам понадобится в дальнейшем, является дельта-функция Дирака. Она определяется как функция равная нулю во всех ненулевых точках, и принимающая в нуле бесконечное значение таким образом, чтобы интеграл от нее по всей вещественной прямой был равен единице.
Ясно, что с точки зрения традиционного математического анализа, такой функции не может быть, поскольку она отличается от нулевой функции значением всего в одной точке, а значение в одной точке не влияет на значение интеграла от этой функции (поэтому интеграл от нее должен быть равен нулю).
На самом деле дельта-функция относится к так называемым обобщенным функциям, вводимым в курсе функционального анализа, однако целый ряд операций можно формально применять к ней и получать верный результат.
Заметим, что для произвольной функции f(x) выполняется следующее равенство:
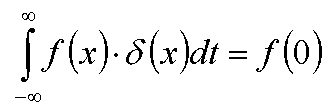
Пусть теперь у нас есть две функции - f1(x) и f2(x). Тогда можно построить функцию, являющуюся их произведением (f1f2)(x)=f1(x)f2(x).
Однако кроме их произведения можно определить еще одну операцию над этими функциями - свертку (convolution).
Свертка функций f1(x) и f2(x) обозначается как (f1*f2)(x) и определяется следующим образом:
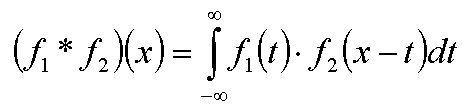
Операции свертки и произведения функций связаны между собой следующим образом:
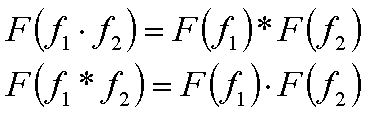
Таким образом, эти операции являются дополнительными друг к другу по отношению к преобразованию Фурье (т.е. преобразование Фурье переводит произведение функций в свертку их спектров и свертку функций переводит в произведение их спектров).
Легко заметить что справедливо следующее равенство:
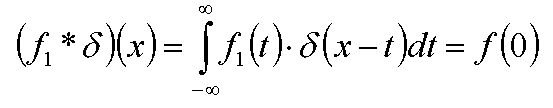
Если мы хотим получить набор значений функции f(x) на сетке с шагом T, то удобно ввести функцию cT(x), определяемую следующим образом:
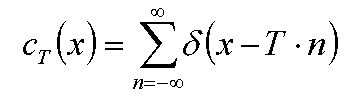
Фактически cT(x) - это набор единичных импульсов с шагом T.
Преобразование Фурье переводит функцию cT(x) в такую же функцию, но уже с другим шагом cT'(x), где T'=2pi/T:
Используя функцию cT(x) можно весь процесс перехода от исходной функции f(x), определенной на некотором интервале вещественной оси, к набору значений на сетке (каждое такое значение называется sample), представить как умножение исходной функции f(x) на функцию cT(x).
Посмотрим, что происходит с образом Фурье (спектром) функции при ее умножении на cT(x):
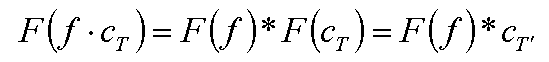
Используя формулу для свертки с дельта-функцией мы получаем следующее равенство:
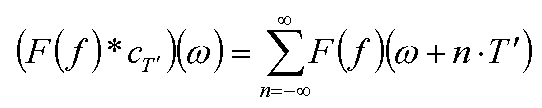
Таким образом спектр функции fcT представляет из себя сумму счетного количества копий (называемых alias'ми) спектра исходной функции, сдвинутых на расстояние кратное T'.
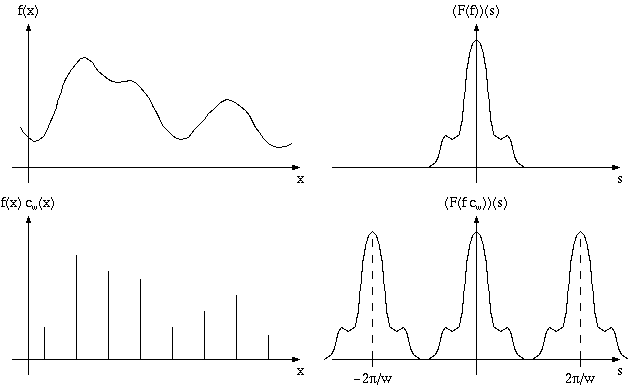
В случае, когда F(f)(w)=0 при |x|>T'/2, то мы просто получаем счетное количество копий исходного спектра, "не налезающих" друг на друга. Поэтому для восстановления исходного спектра функции f(x) достаточно просто умножить спектр на так называемый box-фильтр:
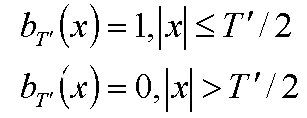
Т.е. в данном случае можно по спектру функции на сетке однозначно восстановить спектр исходной функции, а значит и саму исходную функцию.
Однако если спектр исходной функции оказывается шире, чем |x|>T'/2, то происходит сложение соседних копий (alias'ов) исходного спектра и в результате восстановление исходного спектра (а значит и самой функции) становится невозможным. Это и есть aliasing.
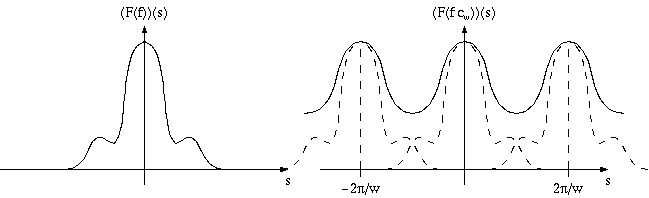
Из этого следует ограничение на максимальный шаг дискретизации (т.е. сетки, T) при переходе от исходной функции, заданной на интервале, к сеточной. Это ограничение в англоязычной литературе обычно называется Nyquist limit, в русскоязычной закрепился термин Теорема Котельникова.
Весьма серьезное применение этой теории лежит не только в выборе правильного шага для дискретизации функции, но и в методах восстановления исходной функции по ее сеточной версии, что имеет место, например, при переходе на другую сетку (т.н. ресэмплинг, resampling).
При этом, поскольку исходная функция f(x) неизвестна, то считается, что шаг сетки удовлетворяет условию однозначной восстановимости спектра исходной функции (даже если это не так, то мы все равно никак исправить это не можем).
В идеале для правильного восстановления исходной функции следует умножить спектр сеточной функции на прямоугольный (box) фильтр - так мы получаем спектр исходной функции - и воспользоваться обратным преобразованием Фурье для получения исходной функции.
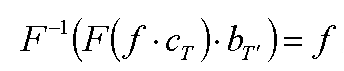
Однако такой подход обычно оказывается неприемлемым из-за необходимости производить прямое и обратное преобразование Фурье (даже в том случае, когда нас интересует значение исходной функции всего в одной точке).
Поэтому обычно работают непосредственно с сеточной функцией без использования преобразования Фурье. В этом случае произведение функций переходит в их свертку:
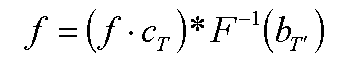
К сожалению образ Фурье для прямоугольного фильтра имеет вид sin(w)/w (так называемая sync-функция) и в отличии от исходного фильтра, обращающегося в ноль всюду кроме небольшого отрезка, отлична от нуля всюду, кроме набора точек, кратных pi.
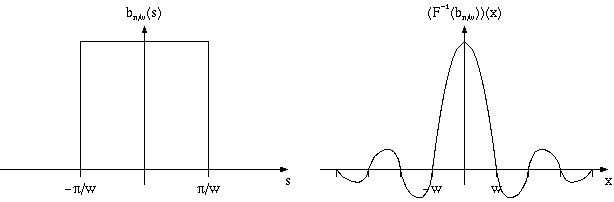
Из этого следует, что свертка с такой функцией оказывается неприемлемой с практической точки зрения.
На практике обычно используют различные варианты фильтров, у всех из которых область, где их образ Фурье отличен от нуля (т.н. носитель), ограничена.
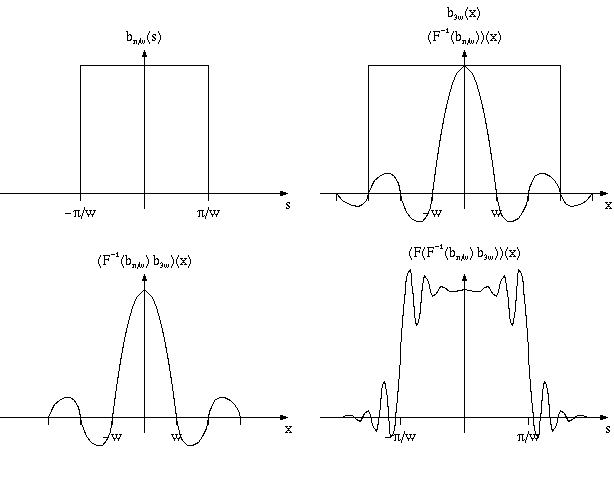
Простейшим примером такого фильтра является уже рассмотренный нами прямоугольный фильтр bd(x), равный нулю вне отрезка [-d,d](и равная 1/(2d) на нем).
Однако использование этого крайне простого фильтра дает крайне плохие результаты, что объясняется тем, что его спектр как раз равен функции sin(w)/w.
Результат применения этого фильтра можно представить как сумму этих фильтров, расположенных в узлах сетки и умноженных на значения функции в этих узлах.
В результате получается просто кусочно-постоянная функция (т.е. это приводит к кусочно-линейной интерполяции).
Несколько лучших результатов можно добиться при использовании треугольного фильтра (также называемого фильтром Бартлетта). На следующем рисунке приведены графики как самого треугольного фильтра, так и его образа Фурье.
Как легко видно из рисунка, применение этого фильтра не обрезает все высокие частоты в спектре функции, а лишь слегка уменьшает их (хотя и в большей степени, чем прямоугольный фильтр).
Применение этого фильтра эквивалентно кусочно-линейной интерполяции (см. следующий рисунок).
Также в качестве ядра свертки можно использовать центральную часть спектра прямоугольного фильтра (обнуляя его значения вне заданного отрезка). К сожалению Фурье-образом для такой функции будет не идеальный прямоугольный фильтр, а его искаженная версия (см. рис).
Довольно часто в качестве фильтра для свертки используется Гауссковский фильтр, где в качестве ядра свертки выступает функция C*exp(-k*x).
Вообще, можно строго доказать что любой фильтр полностью обрезающий все высокие частоты в спектре и мало искажающий низкие, будет иметь неограниченный носитель (точнее его Фурье-образом будет иметь неограниченный носитель).
Перейдем теперь к применению этой теории в компьютерной графике.
Любая текстура на самом деле является сеточной функцией, т.е. набором значений некоторой функции на прямоугольной сетке (см. рис.). Обратите внимание, что цвет задан только в одной точке для каждого прямоугольника разбиения (а не во всем таком прямоугольнике).
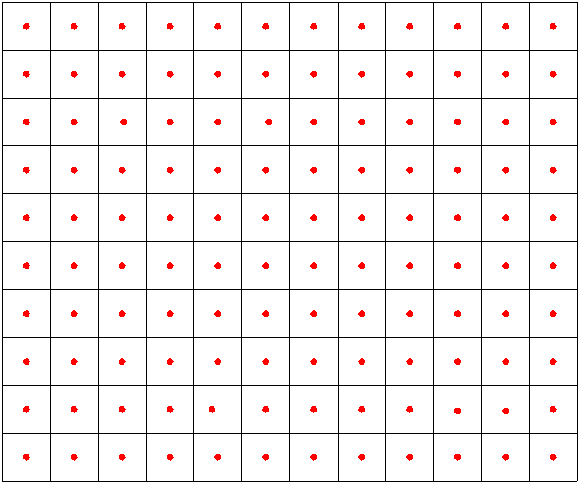
Поэтому когда при текстурировании нам необходимо получить значение текстуры в точке с заданными текстурными координатами, то мы фактически производим восстановление исходной функции в заданной точке, что как было показано выше, есть свертка с некоторым ядром.
Простейшему ядру - прямоугольному фильтру - соответствует режим GL_NEAREST, т.е. кусочно-постоянная интерполяция.
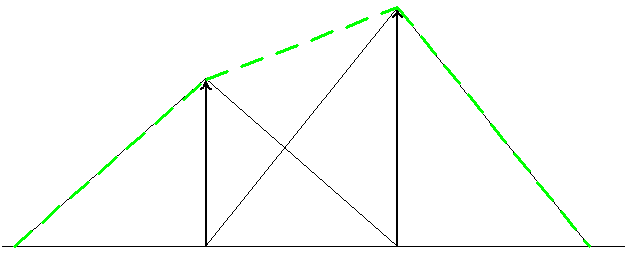
Использование линейного фильтра дает билинейную интерполяцию текстуры - режим GL_LINEAR.
При этом в каждой из четырех ближайших узлов сетки строится пирамида (аналог треугольника для двухмерного случая), высота которой определяется значением цвета и в нужной нам точке значения на этих пирамидах складываются. На следующем рисунке приводится эта операция для одномерной текстуры.
Рассмотрим что происходит при текстурировании достаточно удаленной грани. В этом случаи интересующие нас точки на текстуре (которые соответствуют текстурным координатам пикселов) достаточно сильно удалены друг от друга. Таким образом мы имеем дело фактически с ресэмплингом, т.е. перерасчетом значений на новую сетку, причем с довольно большим шагом.
Чтобы при этом не возникал aliasing необходимо при помощи фильтра убрать слишком высокие (т.е. несоответствующие теореме Котельникова) частоты из исходной текстуры при помощи свертки с некоторым ядром. При этом чем больше новый шаг, тем больше должен быть размер ядра фильтра.
Более того, типичная ситуация заключается в том, что для каждой точки нам нужно ядро своего размера (чем больше расстояние, т.е. степень сжатия текстуры, тем больше должен быть размер ядра).
С практической точки зрения подобный подход явно не приемлем (из-за необходимости использовать ядра разных размеров при текстурировании даже одной грани и возможности появления очень больших ядер свертки). Поэтому используется компромиссный вариант, а именно пирамидальное фильтрование (mipmapping).
Что же представляет из себя пирамидальное фильтрование ?.
Фактически каждый уровень в пирамидальном фильтровании представляет из себя аккуратно выполненный ресэмплинг текстуры с предыдущего уровня с удвоенным шагом (см. рис.).
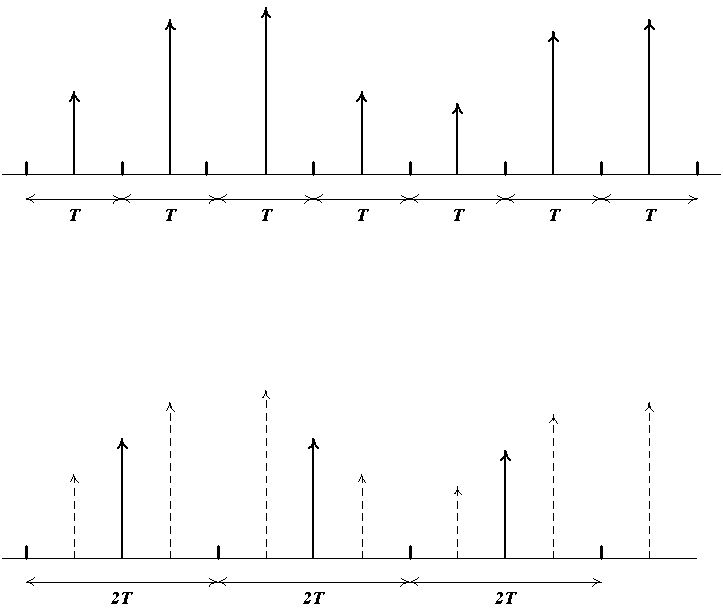
За счет того, что на каждом уровне проводится правильный ресэмплинг текстуры с предыдущего уровня (а не просто бралась каждая 2-я, 4-я и т.д. точка) высокие частоты на каждом уровне подавлялись (хотя и не до конца) и в получившихся текстурах алиасинг практически отсутствует.
При этом если рассматривать уровни пирамиды не относительно предыдущего уровня, а относительно исходной текстуры, то мы получаем, что для каждого последующего уровня происходит ресэмплинг исходной текстуры с вдвое большим (по каждой координате) ядром. Верхнему уровню соответствует ядро, размер которого совпадает с размером самой текстуры.
Таким образом, использование пирамидального фильтрования заключается в том, что берется текстура, уже обработанная при помощи ядра, размер которого достаточно близок к требуемому (но набор имеющихся ядре определен заранее) и на этой текстуре происходит выборка точки при помощи какого-либо фильтра ( обычно линейного).
Трилинейная фильтрация текстуры фактически является попыткой повышения точности, а именно берутся две текстуры, соответствующие двум ядрам (таким, что размер требуемого ядра лежит между размерами этих ядер), при помощи линейной интерполяции получаются два значения (соответствующие этим текстурам и по ним при помощи линейной интерполяции строится окончательное значение.
Такой подход обеспечивает достаточно высокое качество при небольшом числе обращения к текстуре (всего 8 обращений).
При написании данной статьи использовались материалы из следующей статьи SamplingTheory.html.
