|
|
Главная
 Статьи
Ссылки
Скачать
Скриншоты
Юмор
Почитать
Tools
Проекты
Обо мне
Гостевая
Форум
Статьи
Ссылки
Скачать
Скриншоты
Юмор
Почитать
Tools
Проекты
Обо мне
Гостевая
Форум

|
Когда мы обычно рассматриваем программирование GPU на CUDA (можно посмотреть слайды моего курса по CUDA выложены на главной странице, для этой статьи актуальны Лекция 2 и Лекция 8), то там мы не просто разбиваем все запускаемые нити на блоки (с точки зрения Vulkan/OpenGL/OpenCL блоки называются рабочими группами - workgroups). Это разбиение традиционно для всех вычислительных шейдеров и GP GPU API.
Мы рассматриваем еще одно разбиение - нити внутри блока разбиваются на специальные подгруппы, называемыми варпами (warp). Фактически варпы - это группы нитей, которые "как-бы" выполняются параллельно на физическом уровне. В CUDA размер варпа равен 32 нитям.
На самом деле аналогичные понятия есть и в других API, просто используются другие термины - wave, wavefront. Например для AMD блоки (группы) нитей разбиваются на wavefront'ы по 64 нити. Понимание варпов очень важно с точки зрения быстродействия. Но кроме того в CUDA есть целый набор специальных warp-level функций, позволяющих очень эффективный обмен данными между нитями варпа (зачастую даже более эффективный, чем через разделяемую память). Это связано с тем, что все эти функции фактически просто берут значение, лежащее в регистре нити (у каждой нити свой набор регистров) и позволяют быстро выполнить обмен данными между этими регистрами. За счет этого можно более эффективно реализовать ряд алгоритмов (зачастую даже не прибегая к разделяемой памяти).
Возникает естественный вопрос - а что с подобными возможностями у Vulkan. Начиная с версии 1.1 основные возможности для этого вошли в состав Vulkan и ими можно свободно пользоваться. Вместо термина варп/wavefront используется понятие подгруппы (subgroup). Но при этом поддержка работы с подгруппами может быть не только в вычислительных шейдерах, но и ряде других(это определяется возможностями конкретного GPU).
Vulkan 1.1 добавил помимо поддержки данного функционала в GLSL способ получения информации об
аппаратной поддержке устройством.
Вся нужная информация содержится в полях структуры VkPhysicalDeviceSubgroupProperties.
struct VkPhysicalDeviceSubgroupProperties
{
VkStructureType sType;
void* pNext;
uint32_t subgroupSize;
VkShaderStageFlags supportedStages;
VkSubgroupFeatureFlags supportedOperations;
VkBool32 quadOperationsInAllStages;
};
Рассмотрим подробнее значения в этих полях.
subgroupSize - содержит размер подгруппы в нитях, для NVidia обычно он равен 32, для AMD - 64. Должен быть не менее единицы.
supportedStages - битовая маска задающая какие типы шейдеров поддерживают операции с подгруппами.
supportedOperations - битовая маска, задающая какие именно операции поддерживаются.
quadOperationsInAllStages - если в поле supportedOperations выставлен бит VK_SUBGROUP_FEATURE_QUAD_BIT, то содержит
логическое значение, говорящее о том, поддерживаются ли операции над четверками нитей (quad) только в фрагментом шейдере
или же для всей шейдеров, заданных в поле supportedStages
Для получения этой информации перед вызовом функции vkGetPhysicalDeviceProperties2 мы подключаем адрес структуры VkPhysicalDeviceSubgroupProperties
к списку, передаваемому через поле pNext структуры VkPhysicalDeviceProperties2 как показано ниже.
VkPhysicalDeviceProperties2 physicalDeviceProperties;
VkPhysicalDeviceSubgroupProperties subgroupProperties;
subgroupProperties.sType = VK_STRUCTURE_TYPE_PHYSICAL_DEVICE_SUBGROUP_PROPERTIES;
subgroupProperties.pNext = NULL;
physicalDeviceProperties.sType = VK_STRUCTURE_TYPE_PHYSICAL_DEVICE_PROPERTIES_2;
physicalDeviceProperties.pNext = &subgroupProperties;
vkGetPhysicalDeviceProperties2(physicalDevice, &physicalDeviceProperties);
// dump supported shader stages
if ( subgroupProperties.supportedStages & VK_SHADER_STAGE_VERTEX_BIT )
std::cout << "Subgroup vertex shaders supported" << std::endl;
if ( subgroupProperties.supportedStages & VK_SHADER_STAGE_TESSELLATION_CONTROL_BIT )
std::cout << "Subgroup tessellation control shaders supported" << std::endl;
if ( subgroupProperties.supportedStages & VK_SHADER_STAGE_TESSELLATION_EVALUATION_BIT )
std::cout << "Subgroup tessellation evaluation shaders supported" << std::endl;
if ( subgroupProperties.supportedStages & VK_SHADER_STAGE_GEOMETRY_BIT )
std::cout << "Subgroup geometry shaders supported" << std::endl;
if ( subgroupProperties.supportedStages & VK_SHADER_STAGE_FRAGMENT_BIT )
std::cout << "Subgroup fragment shaders supported" << std::endl;
if ( subgroupProperties.supportedStages & VK_SHADER_STAGE_COMPUTE_BIT )
std::cout << "Subgroup compute shaders supported" << std::endl;
// sump supported operation groups
if ( subgroupProperties.supportedOperations & VK_SUBGROUP_FEATURE_BASIC_BIT )
std::cout << "Subgroup basic features supported" << std::endl;
if ( subgroupProperties.supportedOperations & VK_SUBGROUP_FEATURE_VOTE_BIT )
std::cout << "Subgroup vote features supported" << std::endl;
if ( subgroupProperties.supportedOperations & VK_SUBGROUP_FEATURE_ARITHMETIC_BIT )
std::cout << "Subgroup arithmetic features supported" << std::endl;
if ( subgroupProperties.supportedOperations & VK_SUBGROUP_FEATURE_BALLOT_BIT )
std::cout << "Subgroup balloc features supported" << std::endl;
if ( subgroupProperties.supportedOperations & VK_SUBGROUP_FEATURE_SHUFFLE_BIT )
std::cout << "Subgroup shuffle features supported" << std::endl;
if ( subgroupProperties.supportedOperations & VK_SUBGROUP_FEATURE_SHUFFLE_RELATIVE_BIT )
std::cout << "Subgroup shuffle relative features supported" << std::endl;
if ( subgroupProperties.supportedOperations & VK_SUBGROUP_FEATURE_CLUSTERED_BIT )
std::cout << "Subgroup clustered features supported" << std::endl;
if ( subgroupProperties.supportedOperations & VK_SUBGROUP_FEATURE_QUAD_BIT )
std::cout << "Subgroup quad features supported" << std::endl;
if ( subgroupProperties.supportedOperations & VK_SUBGROUP_FEATURE_ROTATE_CLUSTERED_BIT_KHR )
std::cout << "Subgroup clustered rotated features supported" << std::endl;
Добавленные в GLSL функции для работы с подгруппами разбиты на несколько категорий
(которые задаются отдельными битами в supportedOperations).
Каждая категория имеет свое имя - когда-то она была расширением GLSL.
У большинства из них есть GL_ARB_* аналоги, которые работают в OpenGL.
Далее мы рассмотрим их по очереди.
Все вместе они задаются расширением (вошедшим в Vulkan Core) GL_KHR_shader_subgroup.
Важно понимать, что нити подгруппы могут быть активными и неактивными. Простейший пример неактивной нити это когда у нас размер блока (рабочей группы) не кратен размеру подгруппы. Это законно, но нежелательно. В этом случае блок будет дополнен до полного числа подгрупп, но добавленные нити не будут активными.
Другим примером может быть ветвление внутри подгруппы - когда одна часть подгруппы выполняет одну часть условного оператора, а другая часть - другую. Тогда внутри данного оператора часть нитей будет активными, часть пассивными.
Эта самая базовая категория, она включает в себя как набор встроенных переменных, так и набор функций.
Во всех поддерживаемых типах шейдеров доступны следующие встроенные переменные:
gl_SubgroupSize - размер подгруппы в нитях (совпадает с полем subgroupSize в VkPhysicalDeviceSubgroupProperties );
gl_SubgroupInvocationID - уникальный идентификатор нити в подгруппе;
gl_SubgroupEqMask, gl_SubgroupGeMask, gl_SubgroupGtMask, gl_SubgroupLeMask, gl_SubgroupLtMask - битовые маски,
нужны в функциях subgroupBallot*.
В вычислительных шейдерах также доступны следующие дополнительные встроенные переменные:
gl_NumSubgroups - число подгрупп в блоке (рабочей группе);
gl_SubgroupID - идентификатор подгруппы внутри блока.
Кроме этих переменных доступен еще и ряд специальных функций, большинство из которых являются барьерами, т.е. они отвечают за синхронизацию и доступ к памяти. Ниже приводится их описание.
| Функция | Описание |
|---|---|
void subgroupBarrier ()
|
барьер на выполнение и доступ к памяти. Гарантируется что все нити подгруппы прошли барьер и все записи в память, сделанные этими нитями будут видные всем нитям данной подгруппы. |
void subgroupMemoryBarrier ()
|
барьер только на доступ к памяти всех видов. Гарантирует что порядок записей в память одной нитью будет одинаково виден всеми остальными нитями подгруппы. |
void subgroupMemoryBarrierBuffer ()
|
барьер по памяти только для буферов. |
void subgroupMemoryBarrierShared ()
|
барьер по памяти только на разделяемую память. |
void subgroupMemoryBarrierImage ()
|
барьер по памяти только на изображения (слой текстуры). |
bool subgroupElect ()
|
функция вернет true только для одной нити из всей подгруппы, это будет активная нить с наименьшим gl_SubgroupInvocationID. |
Функции данной категории позволяет нитям обмениваться информацией о выполнении некоторого условия для всей подгруппы. При этом условие проверяется для всех нитей подгруппы.
| Функция | Описание |
|---|---|
bool subgroupAll ( bool value )
|
эта функция вернет true, только если все нити подгруппы вызвали ее с параметром true.
|
bool subgroupAny ( bool value )
|
эта функция вернет true, если хотя бы одна нить из подгруппы вызвала ее с параметром true.
|
bool subgroupAllEqual ( T value )
|
вернет true, если все нити подгруппы вызвали ее с одним и тем же значением value.
|
У этой категории есть свой OpenGL аналог - расширение GL_ARB_shader_group_vote. Функции этой группы могут быть очень полезны для оптимизации быстродействия, а именно оптимизации ветвления. Ветвление возникает в подгруппе, если часть нитей пошла по одному пути, а часть по другому. Оно приводит к тому, что фактически подгруппа вынуждена выполнять оба пути.
В помощью функций данной категории мы можем проверить действительно ли для всех нитей подгруппы выполнено некоторое условие и тогда пойти оптимальным путем.
bool condition = checkCondition ();
if ( subgroupAll ( condition ) )
{
// condition is true for all threads in subgroup
}
else
if ( !subgroupAny ( condition ) )
{
// condition is false for all threads in subgroup
}
else
{
// we have branching here
}
Приведенный фрагмент кода показывает, как мы можем обнаруживать когда ветвления не будет (а когда будет) и применять оптимизированные варианты расчета для этих случаев.
Эта категория вводит набор функций, позволяющих нитям подгруппы осуществлять обмен данными. При этом данные функции крайне эффективны, поскольку фактически происходит просто обмен значениями между регистрами - у каждой нити свой набор регистров, не пересекающийся с регистрами другой нити. Эта категория является надмножеством расширения GL_ARB_shader_ballot для OpenGL.
Вводимые данной категорией функции можно разделять на две группы.
Функции первой группы просто раздают одно и то же значение всем нитям подгруппы.
Вторая группа фактически выполняет что-то вроде "голосования" среди нитей подгруппы.
Для хранения состояния этого голосования используется значение типа uvec4, где
каждой нити соответствует один бит.
Гарантируется что места хватит (uvec4 это 32*4=128 бит, что больше размеров подгруппы для основных архитектур).
| Функция | Описание |
|---|---|
T subgroupBroadcast ( T value, uint id )
|
раздает значение value от нити, у которой gl_SubgroupInvocationID равен id,
всем нитям подгруппы (т.е. они все получат одно и то же значение).
Обратите внимание, что значение id должно быть константой времени компиляции.
В другой категории есть вариант данной функции без этого ограничения.
|
T subgroupBroadcastFirst ( T value )
|
раздает всем нитям подгруппы значение value от активной нити с минимальным gl_SubgroupInvocationID
|
uvec4 subgroupBallot ( bool value )
|
значение value от каждой нити определяет один бит в возвращаемой битовой маске как uvec4
|
bool subgroupInverseBallot ( uvec4 value )
|
возвращает true, если соответствующий данной нити бит в маске value равен единице.
|
bool subgroupBallotBitExtract ( uvec4 value, uint index )
|
возвращает true если в переданной битовой маске value бит с номером index равен единице.
|
uint subgroupBallotBitCount ( uvec4 value )
|
возвращает число единичных битов по заданной битовой маске (проверяются только биты, соответствующие нитям подгруппы). |
uint subgroupBallotInclusiveBitCount ( uvec4 value )
|
возвращает inclusive scan по битам из заданной маске. |
uint subgroupBallotExclusiveBitCount ( uvec4 value )
|
возвращает exclusive scan по битам из заданной битовой маске. |
uint subgroupBallotFindLSB ( uvec4 value )
|
возвращает индекс самого младшего равного единице бита в переданной битовой маске. |
uint subgroupBallotFindMSB ( uvec4 value )
|
возвращает индекс самого старшего равного единице бита в переданной битовой маске. |
Обратите внимание, что в командах, принимающих на вход битовую маску, участвуют только биты, соответствующие нитям подгруппы, т.е.
с номерами от 0 до gl_SubgroupSize - 1.
Давайте сейчас рассмотрим что такое inclusive/exclusive scan и зачем он может быть нужен.
В этих функциях битовая маска фактически рассматривается как набор из gl_SubgroupSize чисел (0 или 1) - x0, x1, x2, x3, и т.д.
Тогда exclusive scan по этому массиву строит новый массив, заданный как 0, x0, x0+x2,
x0+x1+x2, x0+x1+x2+x3, и т.д.
А inclusive scan стоит массив x0, x0+x1,
x0+x1+x2, x0+x1+x2+x3 и т.д.
Соответствующая функция возвращает элемент такого массива, соответствующего номеру нити.
Давайте рассмотрим одно из применений функций данной категории. Довольно часто встречается следующий паттерн в вычислительном шейдере - у нас есть большой входной массив объектов и каждая нить вычислительного шейдера проверят один элемент на выполнение некоторого условия (например потенциальной видимости объекта). В случае, когда условие выполнено данный объект записывается в буфер.
Для того, чтобы большое число нитей могло складывать объекты в один большой массив без ошибок (т.е. затирания записанного другой нитью объекта), обычно используется следующий прием - заводится атомарный счетчик (обычно это значение хранится в каком-либо буфере). В нем будем храниться число записанных в буфер элементов, изначально его значение равно нулю.
Каждый раз когда очередная нить определяет что условие для ее объекта выполнена, она выполняет атомарное увеличение этого счетчика на
единицу. При этом функция atmicAdd возвращает старое значение счетчика - это есть уникальный индекс в который нить
может записать свой объект.
bool shouldAdd = checkObject ( gl_GlobalInvocationID );
if ( shouldAdd )
outBuffer [atomicAdd ( counter, 1 )] = currentObject;
Этот прием всегда корректно работает. Но при этом есть одно но - атомарные операции (особенно над содержимым буфера, т.е. глобальной памятью с точки зрения CUDA) очень дорогие с точки зрения быстродействия. Это связано с тем, что когда одновременно поступает несколько атомарных запросов над одной переменной, то они обычно сериализуются, т.е. выполняются по очереди. Если вероятность выполнения условия не является малой, то у нас будет очень большое число атомарных операций над нашим счетчиком.
Можно заметно сократить число вызовов atomicAdd за счет аккуратного использования операций над подгруппами.
Сперва каждая нить подгруппы проверяет условия и мы строим битовую маску, определяющую какие нити будут добавлять объекты в буфер.
Именно они и только они вызывают atomicAdd.
При помощи вызова subgroupBallotBitCount мы можем найти число таких нитей в подгруппе, т.е. на сколько нити подгруппы
должны изменить счетчик.
Тогда мы можем один раз из одной нити вызывать atomicAdd сразу с этим общим числом.
В результате мы сокращаем число атомарных операций во много раз (до 32 на NVidia GPU).
Нам нужно для каждой нити определить индекс, по которому она должна записывать объект в буфер.
Для этого нам идеально подходит exclusive scan над битовой маской.
bool shouldAdd = checkObject ( gl_GlobalInvocationID );
uvec4 mask = subgroupBallot ( shouldAdd );
uint num = subgroupBallotBitCount ( mask );
uint pos = 0; // index where to write value to
if ( subgroupElect () ) // pick one thread to do atomicAdd
pos = atomicAdd ( counter, num );
// broadcast starting index for subgroup
pos = subgroupBroadcast ( pos );
// update index with thread offset within subgroup
pos += subgroupBallotExclusiveBitCount ( mask );
outBuffer[pos] = currentObject;
В этой реализации всего одна нить из подгруппы вызывает atomicAdd.
Т.е. мы заметно сократили число дорогостоящих атомарных операций ценой добавления
нескольких крайне дешевых операций - все эти операции это просто манипуляции над регистрами нитей подгруппы,
не затрагивающими память.
Эта категория вводит ряд арифметических и побитовых операций над значениями, предоставленными каждой нитью - каждая нить дает одно значение и дальше все они комбинируются при помощи арифметических или побитовых операций.
Обратите внимание, что все команды из этой категории работают только для активных нитей группы.
| Функция | Описание |
|---|---|
T subgroupAdd ( T value )
|
вычисляет сумму значений value от всех нитей подгруппы.
|
T subgroupMul ( T value )
|
вычисляет произведение значений value от всех нитей подгруппы.
|
T subgroupMin ( T value )
|
вычисляет минимальное значение value от всех нитей подгруппы.
|
T subgroupMax ( T value )
|
вычисляет максимальное значение value от всех нитей подгруппы.
|
T subgroupAnd ( T value )
|
выполняет побитовое AND над значениями от всех нитей. |
T subgroupOr ( T value )
|
выполняет побитовое OR над значениями от всех нитей. |
T subgroupXor ( T value )
|
выполняет побитовое XOR над значениями от всех нитей. |
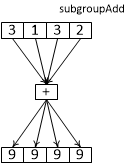
Рис 1.
Кроме этих функций, применяющих требуемую бинарную операцию ко всем полученным значениям,
есть группа аналогичных функций, которую применяют операцию к значениям не от всех нитей,
а либо только предшествующих (exclusive) либо предшествующих и текущей нити (inclusive).
Является ли нить предшествующей по отношению к данной определяется путем сравнения gl_SubgroupInvocationID нитей.
| Функция | Описание |
|---|---|
T subgroupInclusiveAdd ( T value )
|
вычисляет сумму значений value от всех нитей подгруппы с id меньшим или равным |
T subgroupInclusiveMul ( T value )
|
вычисляет произведение значений value от всех нитей подгруппы с id меньшим или равным |
T subgroupInclusiveMin ( T value )
|
вычисляет минимальное значение value от всех нитей подгруппы с id меньшим или равным |
T subgroupInclusiveMax ( T value )
|
вычисляет максимальное значение value от всех нитей подгруппы с id меньшим или равным |
T subgroupInclusiveAnd ( T value )
|
выполняет побитовое AND над значениями от всех нитей с id меньшим или равным |
T subgroupInclusiveOr ( T value )
|
выполняет побитовое OR над значениями от всех нитей с id меньшим или равным |
T subgroupInclusiveXor ( T value )
|
выполняет побитовое XOR над значениями от всех нитей с id меньшим или равным |
T subgroupExclusiveAdd ( T value )
|
вычисляет сумму значений value от всех нитей подгруппы с id меньшим |
T subgroupExclusiveMul ( T value )
|
вычисляет произведение значений value от всех нитей подгруппы с id меньшим |
T subgroupExclusiveMin ( T value )
|
вычисляет минимальное значение value от всех нитей подгруппы с id меньшим |
T subgroupExclusiveMax ( T value )
|
вычисляет максимальное значение value от всех нитей подгруппы с id меньшим |
T subgroupExclusiveAnd ( T value )
|
выполняет побитовое AND над значениями от всех нитей с id меньшим |
T subgroupExclusiveOr ( T value )
|
выполняет побитовое OR над значениями от всех нитей с id меньшим |
T subgroupExclusiveXor ( T value )
|
выполняет побитовое XOR над значениями от всех нитей с id меньшим |
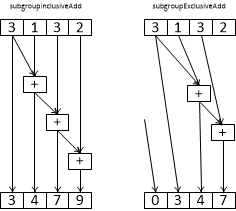
Рис 2.
С помощью функций этой категории можно довольно эффективно выполнять редукцию массива, ниже приводится пример нахождения максимального значения в буфере.
void main()
{
uint value = subgroupMax ( buf [gl_GlobalInvocationID.x] );
// A single invocation in the subgroup will do the atomic operation
if ( subgroupElect () )
atomicMax ( globalMax, value );
}
Данная категория вводит дополнительные функции, реализующие по
сути тот же самый broadcast, но только индекс уже не обязан быть
константой времени компиляции.
Обратите внимание, что если index известен заранее, то лучше использовать ранее рассмотренный subgroupBroadcast, поскольку он
может выполняется более эффективно.
| Функция | Описание |
|---|---|
T subgroupShuffle ( T value, uint index )
|
возвращает значение value от нити, у которой gl_SubgroupInvocationID равен index.
|
T subgroupShuffleXor ( T value, uint mask )
|
возвращает значение value от нити, у которой gl_SubgroupInvocationID равен index XOR mask.
|
Эта категория вводит дополнительные функции для обмена данными между нитями. На самом деле функции данной категории и предыдущей категории являются полными аналогами функций shuffle в CUDA.
| Функция | Описание |
|---|---|
T subgroupShuffleUp ( T value, uint delta )
|
возвращает значение value |
T subgroupShuffleDown ( T value, uint delta )
|
возвращает значение value от нити с номером gl_GlobalInvocationID + delta.
|
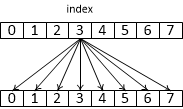
Рис 1. Работа команды subgroupShuffle

Рис 2. Работа команды subgroupShuffleUp
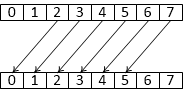
Рис 3. Работа команды subgroupShuffle
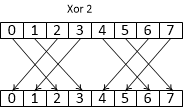
Рис 4. Работа команды subgroupShuffleXor
Следующий пример показывает как можно сделать эффективный inclusive scan с использованием shuffle-функций.
vec4 temp = x;
// This is a custom strided inclusive scan!
for ( uint i = 2; i < gl_SubgroupSize; i *= 2 )
{
vec4 other = subgroupShuffleUp ( temp, i );
if ( i <= gl_SubgroupInvocationID )
temp = temp * other;
}
data = temp;
Данная категория позволяет разбить всю подгруппу на части/кластеры (размера clusterSize) и применять рассмотренные ранее арифметические команды
только внутри каждого кластера.
Обратите внимание, что размер кластера должен быть степенью двух и лежать от одного до gl_SubgroupSize.
| Функция | Описание |
|---|---|
T subgroupClusteredAdd ( T value, uint clusterSize )
|
|
T subgroupClusteredMul ( T value, uint clusterSize )
|
|
T subgroupClusteredMin ( T value, uint clusterSize )
|
|
T subgroupClusteredMax ( T value, uint clusterSize )
|
|
T subgroupClusteredAnd ( T value, uint clusterSize )
|
|
T subgroupClusteredOr ( T value, uint clusterSize )
|
|
T subgroupClusteredXor ( T value, uint clusterSize )
|
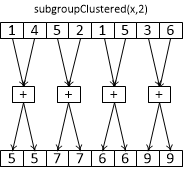
Рис 5.
Известно, что фрагментный шейдер обрабатывает фрагменты группами 2х2 фрагмента, для этого при растеризации могут быть добавлены дополнительные фрагменты, чтобы всегда были полные группу 2х2. Это связано с тем, что для того, чтобы при текстурировании выбрать правильный уровень в mipmap-пирамиде используются производные текстурных координат по экранным координатам. И если мы обрабатываем фрагменты блоками 2х2, то эти производные считаются просто как разности.
Операции данной категории работают именно с кластерами из 4 нитей. Они могут быть доступны не только во фрагментном шейдере, но и в других типах шейдеров. Для фрагментного шейдера гарантируется, что каждый кластер (quad) это именно блок 2х2 фрагмента. Доступны следующие функции:
| Функция | Описание |
|---|---|
T subgroupQuadBroadcast ( T value, uint id )
|
Раздать значение из нити id всем остальным нитям квада
|
T subgroupQuadSwapHorizontal ( T value )
|
Возвращает значение от нити, симметричной по горизонтали (для квада 2x2) |
T subgroupQuadSwapVertical ( T value )
|
Возвращает значение от нити, симметричной по вертикали (для квада 2x2) |
T subgroupQuadSwapDiagonal ( T value )
|
Возвращает значение от нити, диагонально-симметричной (для квада 2x2) |
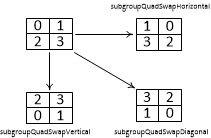
Рис 6.
Есть также расширение VK_KHR_shader_subgroup_rotate (вошедшее в состав Vulkan 1.4), которое вводит ряд дополнительных функций, позволяющих циклически "крутить" значения внутри подгруппы.
| Функция | Описание |
|---|---|
T subgroupRotate ( T value, uint delta )
|
Перемещает value от ните с номером gl_SubgroupInvocationID к нити с номером
(gl_SubgroupInvocationID + delta) % gl_SubgroupSize
|
T subgroupClusteredRotate ( T value, uint delta, uint clusterSize )
|
Перемещает значение value от нити к номером gl_SubgroupInvocationID
к нити с номером
(gl_SubgroupInvocationID - (gl_SubgroupInvocationID % clusterSize)) + ((gl_SubgroupInvocationID % clusterSize + delta) % clusterSize)
|
В OpenGL расширение GL_KHR_shader_subgroup (как и ряд упомянутых ARB-расширений) также доступны.
Но способ получения информации о поддержке следует использовать функции glGetIntegerv и glGetBooleanv.
GLint subgroupSize;
GLint supportedStages;
GLint supportedFeatures;
GLboolean quadAllStages;
glGetIntegerv ( GL_SUBGROUP_SIZE_KHR, &subgroupSize );
glGetIntegerv ( GL_SUBGROUP_SUPPORTED_STAGES_KHR, &supportedStages );
glGetIntegerv ( GL_SUBGROUP_SUPPORTED_FEATURES, &supportedFeatures );
glGetBooleanv ( GL_SUBGROUP_QUAD_ALL_STAGES_KHR, &quadAllStages );

Copyright © Alexey V. Boreskov 2003-2024